ā×╗»ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼īŹ¼F═¼▓Į├ōĄ¬│²╠╝▀^│╠
ųąć°╬█╦«╠Ä└Ē╣ż│╠ŠW ĢrķgŻ║2018-4-25 8:44:06
╬█╦«╠Ä└Ē╝╝ąg | ģRŠ█╚½Ū“Łh▒Ż┴”┴┐Ż¼ĮĄĄ═Ų¾śIų╬╬█│╔▒Š
ĪĪĪĪ1 ę²čį(Introduction)
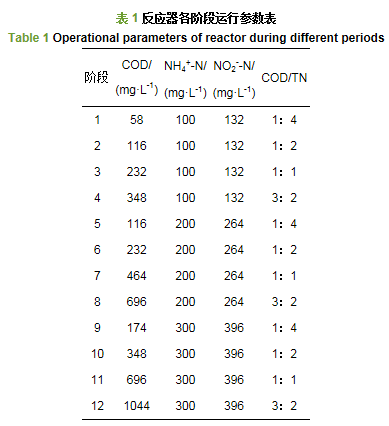
ĪĪĪĪģÆč§░▒č§╗»(Anaerobic Ammonia Oxidation, Anammox)╝╝ągū„×ķĮ³─ĻüĒ│╔╣”čą░lĄ─ą┬ą═╔·╬’├ōĄ¬╝╝ąg, ę“Š▀éõ─▄║─Ą═Īó¤oąĶ═Ō╝ė╠╝į┤Īó«a─Ó┴┐▌^╔┘Ą╚ā׳c╩▄ĄĮ╚╦éāĄ─├▄ŪąĻPūó(║·īÜ╠mĄ╚, 1999;Jetten et al., 1997).─┐Ū░, įō╝╝ągį┌║╔╠mĪóĄż¹£Ą╚ć°ęč│╔╣”▀\ė├ė┌Ž¹╗»╬█─Óē║×Vę║Īó±RŌÅ╩Ē╝ė╣żÅU╦«╝░└¼╗°ØB×Vę║Ą╚ÅU╦«╠Ä└Ē▀^│╠(Li et al., 2015a;╠Ų│ńāĆĄ╚, 2010).ģÆč§░▒č§╗»╩ŪųĖģÆč§░▒č§╗»Š·į┌ģÆč§╗“╚▒觌l╝■Ž┬, ęįNH4+-N×ķļŖūė╣®¾w, NO2--N×ķļŖūė╩▄¾w, īóNH4+-NĪóNO2--N▐D╗»×ķN2Ą─╔·╬’č§╗»▀^│╠(▓▄╠ņĻ╗Ą╚, 2015).į┌ģÆč§░▒č§╗»▀^│╠ųą, ╝sėą11%Ą─┐饬Ģ■▐DūāNO3--N, įņ│╔NO3--NĄ─└█Ęe;═¼Ģr, į┌īŹļH║¼Ą¬ÅU╦«ųą, ę▓═∙═∙┤µį┌ėąÖC╬’(Chen et al., 2016;Li et al., 2015b).NO3--N║═ėąÖC╬’Š∙┐╔▒╗Ę┤Ž§╗»╝ÜŠ·└¹ė├, Ą½┴Ēę╗ĘĮ├µ, Ę┤Ž§╗»╝ÜŠ·ę▓Ģ■═¼ģÆč§░▒č§╗»Š·ĖéĀÄū„×ķļŖūė╩▄¾wĄ─NO2--N, Å─Č°ī¦ų┬ģÆč§░▒č§╗»Š·├ōĄ¬─▄┴”Ą─ĮĄĄ═.─┐Ū░, ęčėąīWš▀(╬║╦╝╝čĄ╚, 2016)ł¾Ą└, ģÆč§░▒č§╗»Š·┐╔ęį┼cŲõ╦¹╝ÜŠ·╣▓┤µ, ╚ńĘ┤Ž§╗»╝ÜŠ·, ▀@ę▓╩╣Ą├└¹ė├ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼ū„ė├īŹ¼F═¼▓Į├ōĄ¬│²╠╝╠Ä└Ē║¼Ą¬║═CODĄ─ÅU╦«│╔×ķ┐╔─▄.«öŪ░, ęčėą▌^ČÓ蹊┐▒Ē├„, COD┼cCOD/TNČ╝Ģ■ė░ĒæģÆč§░▒č§╗»├ōĄ¬ąį─▄, ┴Ēę╗ĘĮ├µ, ū„×ķģÆč§░▒č§╗»╗∙┘|Ą─NH4+-NĪóNO2--Nę▓╩Ūė░ĒæŲõ╣ż╦ćĘĆČ©ąįĄ─ųžę¬ę“╦ž(▓┘╔“▒“Ą╚, 2013;└Ņµ┬, 2014).ChenĄ╚(2016)░l¼F, «ö▀M╦«COD<99.7 mgĪżL-1Ģr, ģÆč§░▒č§╗»├ōĄ¬─▄┴”ėą╦∙╠ß╔², «öCOD▀_ĄĮ284.1 mgĪżL-1Ģr, ģÆč§░▒č§╗»═Ļ╚½▒╗ęųųŲ;╬║╦╝╝čĄ╚(2016)į┌▒Ż│ų▀M╦«COD 300 mgĪżL-1ĪóNO2--N 145 mgĪżL-1Śl╝■Ž┬, ═©▀^Ė─ūāNH4+-N▀M╦«ØŌČ╚░l¼F, ę¬▒Ż│ų┐饬╚ź│²┬╩>94%, COD/NH4+-NųĄę¬┤¾ė┌3.25, NH4+-N/NO2--NųĄę¬ąĪė┌0.63, Ą½╬┤─▄┐╝æ]▀M╦«CODĪóNO2--NĄ╚ę“╦žūā╗»Ą─ė░Ēæ.ę“┤╦, ╚ń║╬┐ņ╦┘Īó£╩┤_Ąž▀x╚Ī╣ż╦ćŚl╝■īŹ¼FģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼═¼▓Į├ōĄ¬│²╠╝, ▓╔ė├é„ĮyĘĮĘ©╚į▌^×ķÅ═ļs└¦ļy, žĮąĶą┬Ą─ĮŌøQ╩ųČ╬.
ĪĪĪĪųŪ─▄╦ŃĘ©ū„×ķ«öŪ░ę╗éĆą┬┼dŅIė“, ę“Š▀ėą¤oąĶ£╩┤_Ą─öĄīW─Żą═ĪóÅŖ┤¾Ą─═Ų└ĒÖCųŲ, ęį╝░Ė„ųŪ─▄╦ŃĘ©ų«ķg┴╝║├Ą─╝µ╚▌ąį║═ŽÓ╗źÅøčaąį, ī”ė┌ĮŌøQÅ═ļsĄ─īŹļHå¢Ņ}ūāĄ├įĮüĒįĮ¤ßķT(Ž“─╚, 2012).į┌ÅU╦«╠Ä└ĒŅIė“ųą, ųŪ─▄╦ŃĘ©Ą─│÷¼F║▄║├ĄžĮŌøQ┴╦ÅU╦«╠Ä└Ē▀^│╠ųąŠ▀ėąĄ─╝s╩°ąįĪóĘŪŠĆąįĪó▓╗┤_Č©ąį║═Į©─Ż└¦ļyĄ╚å¢Ņ}, ─┐Ū░ęčÅVĘ║æ¬ė├ė┌╦«┘|▒O£yĪóģóöĄā×╗»Īó─ŻöMĮ©─ŻĪó╣ż╦ć┐žųŲĄ╚ĘĮ├µ(Ēnéź, 2015;Badrnezhad et al., 2014).BP╦ŃĘ©╩Ū─┐Ū░æ¬ė├ūŅÅVĘ║Ą─╔±ĮøŠWĮjīW┴Ģ╦ŃĘ©, ╦³═©▀^ļ[║¼īėīó▌ö╚ļöĄō■Å─▌ö╚ļīėūā×ķŠWĮj▌ö│÷┴┐, īŹ¼F┐šķgė│╔õ.═©▀^ī”ŠWĮj▌ö│÷║═Ų┌═¹▌ö│÷▀Mąą▒╚▌^, Ė∙ō■╠▌Č╚Ž┬ĮĄĘ©š{š¹ÖÓųž, ų┴ŠWĮj▌ö│÷┼cŲ┌═¹▌ö│÷Ą─Š∙ĘĮ▓Ņ▀_ĄĮūŅąĪ, ╩╣Ą├BP╔±ĮøŠWĮjŠ▀ėą┴╝║├Ą─ĘŪŠĆąįė│╔õ─▄┴”(³S├„ųŪ, 2010).─┐Ū░, ßśī”╗∙ė┌BP╔±ĮøŠWĮjĄ─▄ø£y┴┐─Żą═ęčĮøėą┴╦┤¾┴┐蹊┐, Ųõį┌ÅU╦«╠Ä└ĒųąĄ─▀\ė├ę▓įĮüĒįĮÅV(Ēn韥╚, 2014).
ĪĪĪĪį┌╣ż│╠ųąĮø│ŻĢ■ė÷ĄĮ╚ńīŹ¼FģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼═¼▓Į├ōĄ¬│²╠╝┤╦ŅÉĄ─ČÓ£╩ät╗“ČÓįOėŗ─┐ś╦Ž┬Ą─įOėŗ║═øQ▓▀å¢Ņ}, ▀@ą®─┐ś╦═∙═∙ŽÓŃŻ, ꬚ęĄĮØMūŃ▀@ą®─┐ś╦Ą─ūŅ╝čįOėŗĘĮ░Ė, Š═ę¬ĮŌøQČÓ─┐ś╦║═ČÓ╝s╩°Ą─ā×╗»å¢Ņ}(Ė▀µ┬, 2006).é„ĮyĄ─ČÓ─┐ś╦ā×╗»ĘĮĘ©, ╚ń╝ėÖÓĘ©Īó╝s╩°Ę©Īó╗ņ║ŽĘ©Īó─┐ś╦ęÄäØĘ©ĪóūŅ┤¾ūŅąĪĘ©Ą╚, ę“┤µį┌ų„ė^ąį┤¾Īóā×╗»▀Mš╣▓╗┐╔▓┘ū„Ą─╚▒³c, į┌╠Ä└ĒĖ▀ŠSöĄĪóČÓ─ŻæBĪóĘŪŠĆąįĄ╚Å═ļså¢Ņ}╔Ž┤µį┌įSČÓ▓╗ūŃ(ėÓ═óĘ╝Ą╚, 2013).į┌2002─Ļ, DebĄ╚(2000)╠ß│÷┴╦ĘŪ│ŻĮøĄõĄ─┐ņ╦┘ĘŪų¦┼õ┼┼ą“▀zé„╦ŃĘ©NSGA-ó“, ╦∙Ū¾Ą─ūŅā×ĮŌ╝»─▄ē“║▄║├Ąž▒ŲĮ³ParetoŪ░čž, ╦∙▓╔ė├Ą─ŠÓļxōĒöDÖCųŲ╩╣Ą├ūŅā×ĮŌ╝»ōĒėą┴╝║├Ą─Ęų▓╝, ę“Ųõ┴╝║├Ą─ŠC║Žąį─▄Č°▒╗ÅVĘ║æ¬ė├ĄĮīŹļHŽĄĮyįOėŗųą(Huang et al., 2016).Ēnéź(2015)╗∙ė┌╔±ĮøŠWĮj║═NSGA-ó“įOėŗ│÷Ą─ę╗╠ūßśī”įņ╝łÅU╦«Ą─┐žųŲ-ŅA£y-ā×╗»ŽĄĮy, ×ķųŪ─▄╦ŃĘ©į┌įņ╝łÅU╦«ģÆč§╠Ä└ĒĄ─æ¬ė├╠ß╣®┴╦Ä═ų·.ī”ė┌▀^│╠Ė³×ķÅ═ļsĄ─ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼å¢Ņ}ģs║▄╔┘ėą╚╦╔µ╝░.
ĪĪĪĪ▒Š╬─ęįģÆč§░▒č§╗»┼cĘ┤Ž§╗»▀^│╠×ķ蹊┐ī”Ž¾, ęįNH4+-N║═COD╚ź│²ą¦╣¹═¼ĢrūŅ┤¾╗»×ķ─┐Ą─, ═©▀^Į©┴óŲĄ─PCA-BPŅA£yŠWĮj║═NSGA-ó“ā×╗»ŠWĮj, ī”ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼īŹ¼F═¼▓Į├ōĄ¬│²╠╝▀^│╠▀Mąąā×╗», ┤_Č©▀M╦«NH4+-NĪóNO2--N║═pHĄ╚ģóöĄĄ─ūŅ╝č╚ĪųĄ.ęįŲ┌×ķ┤╦ŅÉÅU╦«╠Ä└Ē▀^│╠┤µį┌Ą─ģf═¼ā×╗»å¢Ņ}║═ųŪ─▄╦ŃĘ©Ą─īŹļHæ¬ė├╠ß╣®ģó┐╝║═ųĖī¦.
ĪĪĪĪ2 ▓─┴Ž┼cĘĮĘ©(Materials and methods)2.1 īŹ“×čbų├║═╣żū„Śl╝■
ĪĪĪĪīŹ“×čbų├▓╔ė├╚ńłD 1╦∙╩ŠĄ─╔Ž┴„╩ĮģÆč§╬█─Ó┤▓(Up-flow Anaerobic Sludge Bed, UASB)čbų├, Ųõ▓─┘|×ķėąÖC▓Ż┴¦, Ę┤æ¬Ų„ėąą¦╚▌Ęe×ķ25.12 L, Ųõųą, Ę┤æ¬ģ^╚▌Ęe×ķ18.12 L, │┴ĄĒģ^╚▌Ęe×ķ7 L.Ę┤æ¬Ų„═Ō░³╣³║┌▓╝ęįĘ└ų╣╣Ōč§╗»Š·Ą─ė░Ēæ.─ŻöMÅU╦«ė╔BT600-2Ją═╚õäė▒├ĮøĘ┤æ¬Ų„Ąū▓┐▓╝╦«ŽĄĮy▀M╚ļĘ┤æ¬Ų„, ═©▀^┐žųŲ▒├Ą─▐D╦┘┐žųŲÅU╦«═Ż┴¶Ģrķg, ÜŌĪó─ÓĪó╦«╗ņ║Žę║═©▀^įOį┌Ę┤æ¬Ų„Ēö▓┐Ą─╚²ŽÓĘųļxŲ„Ęųļx, │÷╦«ė╔ęń┴„č▀┼┼│÷.╦«┘|ģóöĄį┌ŠĆ▒O£yŽĄĮyė╔į┌ŠĆpHāx▒Ē(├└ć°╣■ŽŻ╣½╦Š, GLI MODEL33)║═ر╩ĮÜŌ¾w┴„┴┐ėŗ(LML-1ą═)ĮM│╔.īŹ“×╦∙ė├ĮėĘN╬█─Ó×ķÅVų▌─│╬█╦«ÅSģÆč§Č╬╬█─Ó, Ę┤æ¬Ų„Įø6éĆį┬│╔╣”åóäė▓ó▀_ĄĮĘĆČ©ĀŅæB.į┌HRT×ķ8 hĢr, ░▒Ą¬Īóü厧╦ß¹}Ą¬║═┐饬Ą─╚ź│²žō║╔Ęųäe×ķ0.56Īó0.76║═1.32 kgĪżm-3Īżd-1.į┌ĘĆČ©ļAČ╬, ░▒Ą¬╚ź│²Īóü厧╦ß¹}Ą¬╚ź│²┼cŽ§╦ß¹}Ą¬Ą─╔·│╔▒╚×ķ1Ż║(1.25Ī└0.03)Ż║(0.28Ī└0.02), ĮėĮ³ė┌└ĒšōųĄ.
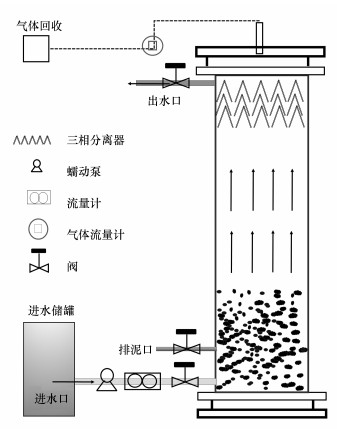
ĪĪĪĪłD 1 UASBĘ┤æ¬Ų„╩ŠęŌłD
ĪĪĪĪīŹ“×▓╔ė├╚╦╣żūį┼õÅU╦«, ų„ę¬│╔Ęų×ķ(mgĪżL-1)Ż║KH2PO4 10, CaCl2Īż2H2O 5.6, MgSO4Īż7H2O 300, NaHCO3 1250, ╬ó┴┐į¬╦žØŌ┐sę║Ė„1.25 mL, Š▀¾wĮMĘųģóęŖWangĄ╚(2009)ĘĮĘ©═Č╝ė.NH4+-NĪóNO2--N║═CODė╔NH4ClĪóNaNO2║═ŲŽ╠č╠Ū░┤ąĶ╠ß╣®, ┐žųŲ▀M╦«NH4+-N┼cNO2--N╬’┘|Ą─┴┐▒╚×ķ1Ż║1.32, ė├╠╝╦ßÜõŌcš{╣Ø▀M╦«pHį┌7.3~7.8ų«ķg.▀M╦«NH4+-NĪóNO2--N║═CODĄ─╦«┘|ųĖś╦ęŖ▒Ē 1.īŹ“×Ų┌ķg, NH4+-N£yČ©▓╔ė├╝{╩ŽĘų╣Ō╣ŌČ╚Ę©, NO2--N£yČ©▓╔ė├▌┴ęęČ■░ĘĘų╣Ō╣ŌČ╚Ę©, COD£yČ©▓╔ė├ųžŃt╦ßŌøĄ╬Č©Ę©.
ĪĪ
ĪĪĪĪ2.2 PCA-BP─Żą═Ą─Į©┴ó
ĪĪĪĪBP(Backpropagation)╔±ĮøŠWĮj╩Ūę╗ĘNŠ▀ėą▀B└mé„▀f║»öĄĄ─ČÓīėŪ░ü╚╦╣ż╔±ĮøŠWĮj, ęįŠ∙ĘĮš`▓ŅūŅąĪ╗»×ķ─┐ś╦, Ųõė¢ŠÜĘĮ╩Į▓╔ė├š`▓ŅĘ┤Ž“é„▓ź╦ŃĘ©, ═©▀^▓╗öÓą▐Ė─ŠWĮjĄ─ÖÓųĄ║═ķōųĄ, ūŅĮK▀_ĄĮĖ▀Š½Č╚öM║ŽöĄō■Ą─ĘŪŠĆąį▓╗┤_Č©ąįöĄīW─Żą═(äó┤║ŲGĄ╚, 2013).į┌īŹļH╩╣ė├▀^│╠ųą, ė╔ė┌ßśī”ģÆč§░▒č§╗»Ą─ÅU╦«╠Ä└Ē┐žųŲ▀^│╠╩Ūę╗éĆ░³║¼ČÓūā┴┐ĪóČÓ─┐ś╦ĪóČÓīė┤╬Ą─ėąų°║Ż┴┐ą┼ŽóĄ─Å═ļsŽĄĮy, ŲõĖ„ĘN╦«┘|ģóöĄų«ķg┤µį┌ÅŖ┴ę±Ņ║Ž║═ĻP┬ōĄ─Ūķør, ę“┤╦, ▒Š╬─▓╔ė├PCA(Principal Component Analysis)Įę╩ŠĖ„▀^│╠ūā┴┐ķgĄ─ŠĆąįŽÓĻPĻPŽĄ, īóČÓéĆŽÓĻPūā┴┐▐D╗»×ķ╔┘öĄÄūéĆŽÓ╗ź¬Ü┴óūā┴┐, īŹ¼F▌ö╚ļöĄō■ĮĄŠS, ╝┤▌oų·ūā┴┐Ą─Š½▀x(äó▓®Ą╚, 2015;╚ĮŠS¹ÉĄ╚, 2004).
ĪĪĪĪPCA╩Ūę╗ĘNĮyėŗŽÓĻPĘų╬÷╝╝ąg, ╩Ūū„×ķ▌ö╚ļöĄō■╝»ĮĄŠS║═Įę╩Šūā┴┐ķgŠĆąįŽÓĻPĻPŽĄĄ─╣żŠ▀(Yao et al., 1997).ų„į¬Ęų╬÷Ą─╗∙▒Š╦╝Žļ╩Ūį┌▒ŻūCöĄō■ą┼ŽóüG╩¦ūŅ╔┘Ą─įŁätŽ┬, ī”Ė▀ŠSūā┴┐┐šķg▀MąąĮĄŠS╠Ä└ĒĘų╬÷, ╩╣Ą═ŠS╠žš„Ž“┴┐ųąĄ─ų„│╔Ęųūā┴┐─▄▒Ż┴¶įŁ╩╝ūā┴┐Ą─╠žš„ą┼ŽóŻ¼═¼ĢrŽ¹│²╚▀ėÓą┼Žó(Jolliffe et al., 2016).
ĪĪĪĪ╗∙ė┌PCA-BP╔±ĮøŠWĮjĄ─ŅA£y─Żą═Ą─ų„ę¬Į©─Ż▓Į¾E╚ńŽ┬Ż║ó┘įŁ╩╝öĄō■Ą─½@╚Ī, ═©▀^Ė─ūā▀M╦«Śl╝■, UASBģÆč§Ę┤æ¬Ų„│╔╣”▀\ąą150 d, į┌┤╦Ų┌ķg½@Ą├▀M╦«NH4+-NĪóNO2--NĪóCODĪópH║═│÷╦«NH4+-NĪóCODĪópHĄ╚ČÓĒŚųĖś╦;ó┌öĄō■ŅA╠Ä└Ē, ░³└©öĄō■«É│ŻųĄĄ─╠▐│²║═Üwę╗╗»▓┘ū„, Ųõ─┐Ą─į┌ė┌┤_▒Ż─Żą═Ą─▌ö╚ļ║═▌ö│÷ųĄĄ─ĮyėŗĘų▓╝┤¾ų┬Š∙ä“, Å─Č°╠ßĖ▀─Żą═Ą─▀\ąąŠ½Č╚╝░▀\ąą╦┘Č╚;ó█īó▓Į¾Eó┌½@Ą├Ą─öĄō■└¹ė├PCA▀MąąöĄō■ĮĄŠS, ═©▀^ėŗ╦Ń└█ėŗĘĮ▓ŅžĢ½I┬╩, ┤_Č©ų„│╔ĘųéĆöĄ, ĮM│╔ą┬Ą─öĄō■śė▒ŠŠžĻćīŹ¼FöĄō■ĮĄŠS;ó▄└¹ė├▓Į¾Eó█ųą½@╚ĪĄ─ą┬Ą─śė▒ŠöĄō■, └¹ė├BP╦ŃĘ©Į©┴óŲŅA£y─Żą═;┤_┴óBP╔±ĮøŠWĮjĄ─│§╩╝ÖÓųĄ║═ķōųĄ, ▓ó═©▀^Ī░įćÕeĘ©Ī▒┤_Č©ļ[║¼īė╔±Įøį¬öĄ, ▀Mąąė¢ŠÜ┼c£yįć;ó▌öĄō■┐╔ęĢ╗»▌ö│÷, īóūŅĮKĄ├ĄĮĄ─ĮY╣¹ęįłD▒Ēą╬╩Į▌ö│÷ęį╣®Ęų╬÷.
ĪĪĪĪ2.3 ╗∙ė┌PCA-BP║═NSGA-ó“Ą─ČÓ─┐ś╦ā×╗»─Żą═
ĪĪĪĪNSGA-ó“╦ŃĘ©╩Ū╗∙ė┌NSGA(Non-Dominated Sorting in Genetic Algorithms)╦ŃĘ©▀MąąĖ─▀M, ė├ė┌ĮŌøQČÓ─┐ś╦ā×╗»å¢Ņ}(Deb et al., 2000).ßśī”NSGA-ó“╦ŃĘ©Ą─Į©┴óąĶę¬ĻPė┌ā×╗»─┐ś╦å¢Ņ}Ą─öĄīW─Żą═, ī”ė┌ģÆč§░▒č§╗»Ą╚ÅU╦«╠Ä└Ē╣ż╦ćČ°čį, ė╔ė┌Ė„ģóöĄ┴┐┼cā×╗»─┐ś╦ų«ķg═∙═∙╩ŪĘŪŠĆąįŪęÅ═ļsĄ─ĻPŽĄ, é„ĮyĄ─ÖC└ĒĮ©─Ż¤oĘ©ū÷ĄĮ, ▒Š╬─ųą═©▀^▓╔ė├PCA-BP╔±ĮøŠWĮj║▄║├Ąž─ŻöM│÷Ė„ģóöĄ┴┐┼cā×╗»─┐ś╦┴┐ų«ķgĄ─ĻPŽĄ, īóįō─Żą═┤·╠µé„ĮyĄ─öĄīW─Żą═ė├ė┌NSGA-ó“╦ŃĘ©ųąĮŌøQģÆč§░▒č§╗»╠Ä└Ē▀^│╠ųą┤µį┌Ą─ČÓ─┐ś╦ā×╗»å¢Ņ}, ūŅĮKĮ©┴óŲ╗∙ė┌PCA-BP║═NSGA-ó“ŽÓĮY║ŽĄ─ČÓ─┐ś╦ā×╗»─Żą═.▒Š╬─ųą─Żą═Š∙į┌Matlab2015b▄ø╝■ŲĮ┼_ĪóWindows10ŁhŠ│Ž┬Į©┴ó.NAGA-ó“╦ŃĘ©Ą─╗∙▒Š┴„│╠╚ńłD 2╦∙╩Š.
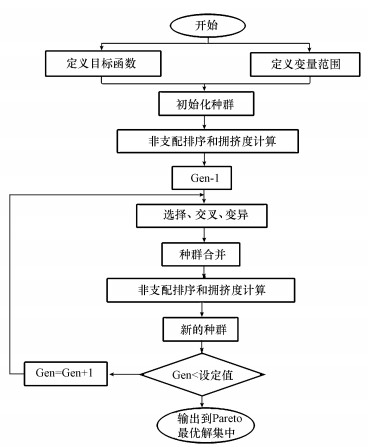
ĪĪĪĪłD 2ā×╗»─Żą═┴„│╠╩ŠęŌłD
ĪĪĪĪßśī”ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼īŹ¼F═¼▓Į├ōĄ¬│²╠╝, Į©┴ó╚ńŽ┬ā×╗»─Żą═, ─┐ś╦║»öĄ╚ń╩Į(1)║═(2)╦∙╩Š, ╝s╩°Śl╝■ęŖ╩Į(3).

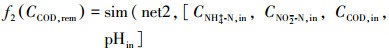
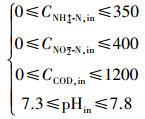
ĪĪĪĪ╩Įųą, net1Īónet2Ęųäe×ķ╗∙ė┌PCA-BP╦ŃĘ©Į©┴óĄ─NH4+-N║═COD╚ź│²ØŌČ╚ŅA£y─Żą═, CNH4+-N, inĪóCNO2--N, inĪóCCOD, inĪópHinĘųäe┤·▒Ē▀M╦«NH4+-NĪóNO2--NĪóCOD║═pH, ▀Mę╗▓Į▀x╚ĪNSGA-ó“ģóöĄ×ķŻ║ĘN╚║öĄ┴┐100ĪóĮ╗▓µĖ┼┬╩0.4Īóūā«ÉĖ┼┬╩0.05ĪóūŅ┤¾▀M╗»┤·öĄ500.
ĪĪĪĪ2.4 įŁ╩╝öĄō■Ą─▓╔╝»╝░PCA╠Ä└Ē
ĪĪĪĪUASBĘ┤æ¬Ų„│╔╣”åóäėų«║¾▀MąąöĄō■▓╔╝»╣żū„, ═©▀^Ė─ūā▀M╦«Śl╝■, Ę┤æ¬Ų„▀B└m▀\ąą╣żū„150 d.▓╔╝»ĄĮĄ─öĄō■╠▐│²├„’@«É│ŻųĄ║¾└¹ė├└Łę└▀_£╩ät╠▐│²ļx╚║ųĄ, ╣▓Ą├ĄĮ144ĮMį¬öĄō■.īŹ“×▀x╚ĪĄ──Żą═▌ö╚ļ┴┐░³└©▀M╦«NH4+-NĪóNO2--NĪóCOD║═pH 4ĒŚ▓┘ū„ūā┴┐, ęįCOD║═NH4+-N╚ź│²ØŌČ╚ū„×ķ─Żą═▌ö│÷ūā┴┐.×ķŽ¹│²┴┐ŠVė░Ēæ, ╠ßĖ▀─Żą═▀\╦Ń╦┘Č╚, └¹ė├╣½╩Į(4)ī”įŁ╩╝öĄō■▀MąąÜwę╗╗»╠Ä└ĒŻ║
ĪĪĪĪ╩Įųą, S(i)×ķöĄō■╝»ųąĄ─ę╗ĮMöĄō■;max(S)×ķöĄō■╝»ųąūŅ┤¾Ą─ę╗ĮMöĄō■;min(S)×ķöĄō■╝»ųąūŅąĪĄ─ę╗ĮMöĄō■.
ĪĪĪĪĮøÜwę╗╗»╠Ä└Ē║¾Ą─öĄō■╩╣ė├MATLAB 2015b▄ø╝■▀MąąPCAĮĄŠS▓┘ū„, ═©▀^Ęų╬÷Ė„éĆūā┴┐Ą─ŽÓĻPąįĮĄĄ═▌ö╚ļöĄō■ŠSöĄ, ╚ź│²╚▀ėÓą┼Žó╝░£p╔┘BPĄ─ėŗ╦Ń┴┐.╠Ä└ĒĮY╣¹╚ńłD 3╦∙╩Š, ļpś╦łD(łD 3a)’@╩Š┴╦▌oų·ūā┴┐┼cśė▒Š³cų«ķgĄ─ČÓį¬ĻPŽĄ, ▀BĮėįŁ³c║═Ė„ūā┴┐Ą─ų▒ŠĆĘQ×ķĪ░Ž“┴┐Ī▒, Ųõį┌─│ę╗ų„│╔Ęų╔ŽĄ─═Čė░▒Ē├„įōūā┴┐ī”įōų„│╔ĘųĄ─ųžę¬│╠Č╚, ═¼Ģrę▓¾w¼F┴╦įōų„│╔Ęųī”įōūā┴┐Ą─ĮŌßī│╠Č╚(äó▓®Ą╚, 2015).Å─łD 3aųąūā┴┐Ą─╩Ė┴┐ķLČ╚┐╔ęį┐┤│÷, ▀M╦«NH4+-NĪóNO2--NØŌČ╚║═▀M╦«pHČ╝╩Ū╩«Ęųųžę¬Ą─ė░Ēæūā┴┐, ŽÓī”üĒšf, ▀M╦«CODĄ─ė░Ēæ▌^ąĪ.Å─łD 3b┐╔ęį┐┤│÷, Ą┌ę╗ų„│╔ĘųĄ─ĘĮ▓ŅžĢ½I┬╩×ķ71.58%, Ą┌Č■ų„│╔ĘųĄ─ĘĮ▓ŅžĢ½I┬╩×ķ17.21%, ┐éžĢ½I┬╩×ķ88.79%, ī┘ė┌ųąĄ╚Ų½╔ŽĄ─öM║ŽČ╚╦«ŲĮ;Ė∙ō■ų„│╔ĘųĄ─ę╗░Ń▀xätś╦£╩, └█ėŗĘĮ▓ŅžĢ½I┬╩Ī▌85%Ą─Ū░kéĆų„│╔Ęų─▄ē“░³║¼Į^┤¾▓┐Ęųą┼Žó, ║¾├µĄ─Ųõ╦¹│╔Ęųät┐╔ęį╔ߌē, ▀@└’įŁüĒĄ─4ĒŚųĖś╦╝┤┐╔ė╔▀@2éĆų„│╔Ęų┤·╠µ.
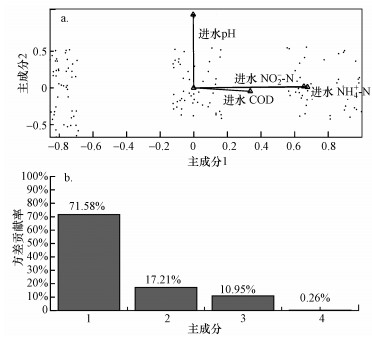
ĪĪĪĪłD 3ļpś╦łD(a)║═ĘĮ▓ŅžĢ½I┬╩(b)
ĪĪĪĪ▒Š╬─▀x╚Ī3éĆįuārųĖś╦ė├ęį▒Ēš„─Żą═ŅA£yąį─▄, Ųõųą, MAPE(Mean Absolute Percent Error)╩Ū╦∙ėąŽÓī”š`▓ŅĄ─Į^ī”ųĄŪ¾║═Ą─ŲĮŠ∙ųĄ, ─▄Å─š¹¾w╔ŽĖ³║├ĄžĘ┤ė│ŅA£yųĄĄ─īŹļHŪķør;RMSE (Root Mean Square Error)╩Ūė^£yųĄ┼cšµīŹųĄŲ½▓ŅĄ─ŲĮĘĮ┼cė^£y┤╬öĄn▒╚ųĄĄ─ŲĮĘĮĖ∙, ┐╔ęįšf├„śė▒ŠĄ─ļx╔ó│╠Č╚, RMSEųĄįĮąĪ, šf├„ŅA£y─Żą═├Ķ╩÷īŹ“×öĄō■Ą─Š½┤_│╠Č╚įĮĖ▀, Ę┤ų«ęÓ╚╗;r(correlation coefficient)Ę┤ė│┴╦ŅA£yųĄ┼cīŹļHųĄŠĆąįĻPŽĄĄ─ÅŖ╚§, rųĄįĮĮėĮ³ė┌1, ┤·▒ĒŅA£yųĄ┼cīŹļHųĄįĮĮėĮ³(äó┴ųĄ╚, 2017).
ĪĪĪĪ3 ĮY╣¹┼cėæšō(Results and discussion)3.1 PCA-BP─Żą═ŅA£yĘ┬šµ
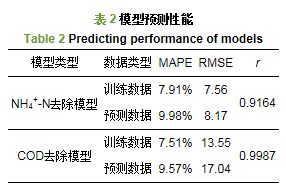
ĪĪĪĪĮY║Ž╔Ž╬─, įŁ╩╝öĄō■ĮøÜwę╗╗»║═PCA╠Ä└Ē║¾, ĘųäeĮ©┴óŲ╗∙ė┌BP╔±ĮøŠWĮjĄ─NH4+-N║═COD╚ź│²ØŌČ╚ŅA£y─Żą═, Ųõųą, ▌ö╚ļīė×ķ▀M╦«NH4+-NĪóNO2--NĪóCOD║═pH, ▌ö│÷īėĘųäe×ķNH4+-N║═COD╚ź│²ØŌČ╚, ═©▀^įćÕeĘ©▀xė├5éĆ╣سcū„×ķļ[║¼īė╣سc, ─Żą═Ą─═žōõĮYśŗūŅĮK×ķ4-5-1.Å─īŹ“לė▒Šųą▀x╚Ī120ĮMöĄō■ū„×ķė¢ŠÜśė▒Š, 24ĮMöĄō■ū„×ķÖz“לė▒Š.ųĄĄ├ūóęŌĄ─╩Ū, ─Żą═Ą─ė¢ŠÜśė▒Š║═Öz“לė▒ŠĄ─▀x╚ĪČ╝æ¬░³║¼ČÓĘNŚl╝■.▀xė├║»öĄtansig║═logsigū„×ķļ[║¼īė║═▌ö╚ļīė╔±Įøį¬Ą─é„▀f║»öĄ, ▀xė├║»öĄtrainlmū„×ķė¢ŠÜ║»öĄ.ŠWĮjĄ─īW┴Ģ╦┘┬╩×ķ0.3, īW┴Ģäė┴┐│ŻöĄ×ķ0.001, ─┐ś╦š`▓Ņ×ķ0.015, ūŅ┤¾Ą³┤·×ķ1000┤╬.Ę┬šµĮY╣¹╚ńłD 4║═▒Ē 2╦∙╩Š.
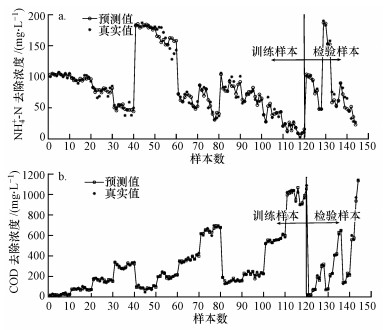
ĪĪĪĪłD 4 PCA-BP─Żą═ī”NH4+-N (a)║═COD (b)╚ź│²Ą─Ę┬šµĮY╣¹
ĪĪ
ĪĪĪĪÅ─łDųą┐╔ęį┐┤│÷, ─Żą═ŅA£yųĄ┼cīŹļHšµīŹųĄ╗∙▒Š┌ģ═¼.ė╔▒Ē 2┐╔ų¬, Öz“לė▒Šųąī”NH4+-N╚ź│²ØŌČ╚Ą─ŅA£yųĄ║═šµīŹųĄų«ķgĄ─ŲĮŠ∙ŽÓī”š`▓Ņ×ķ9.98%, Š∙ĘĮĖ∙š`▓Ņ×ķ8.17, ŅA£yöĄō■┼cīŹļHöĄō■Ą─ŽÓĻPŽĄöĄ×ķ0.9164;Č°ī”CODČ°čį, ŲõŅA£yųĄ┼cšµīŹųĄų«ķgĄ─ŲĮŠ∙ŽÓī”š`▓Ņ×ķ9.57%, Š∙ĘĮĖ∙š`▓Ņ×ķ8.17, ŅA£yöĄō■┼cīŹļHöĄō■Ą─ŽÓĻPŽĄöĄ×ķ0.9987.ā╔─Żą═Ą─ŲĮŠ∙ŅA£yš`▓ŅČ╝į┌10%ęįā╚, ▀@▒Ē├„BP╔±ĮøŠWĮjŠ▀ėą║▄║├Ą─ŅA£y─▄┴”╝░┴╝║├Ą─ĘŪŠĆąįė│╔õ─▄┴”, ─▄ē“ū„×ķNSGA-ó“Ą──┐ś╦║»öĄ.Š▀¾w┬ōŽĄ╬█╦«īÜ╗“ģóęŖhttp://www.bnynw.comĖ³ČÓŽÓĻP╝╝ąg╬─ÖnĪŻ
ĪĪĪĪ3.2 ╗∙ė┌PCA-BP║═NSGA-ó“Ą─ČÓ─┐ś╦ā×╗»Ą─īŹ¼F
ĪĪĪĪ─Żą═ā×╗»ĮY╣¹╚ńłD 5╦∙╩Š, ė╔łDųąParetoūŅā×▀ģĮń³c┐╔ęį┐┤│÷, │÷╦«NH4+-N╚ź│²ØŌČ╚║═COD╚ź│²ØŌČ╚ų«ķg┤µį┌╗“ät▀@śėĄ─ĻPŽĄŻ║«ö│÷╦«NH4+-N╚ź│²ØŌČ╚╠ßĖ▀Ģr, │÷╦«COD╚ź│²ØŌČ╚ļSų«Ž┬ĮĄ, Ę┤ų«ęÓ╚╗.×ķų▒ė^ĄžÅ─öĄīW─Żą═ĮŪČ╚ĮŌßīŅA£y─Żą═ųąNH4+-N╚ź│²ØŌČ╚║═COD╚ź│²ØŌČ╚ų«ķgĄ─ŠĆąįĻPŽĄ, ▀\ė├MATLABĄ─Š█ŅÉČÓĒŚ╩ĮŠĆąįöM║Ž╣żŠ▀▀MąąöM║Ž, │÷╦«NH4+-N╚ź│²ØŌČ╚║═COD╚ź│²ØŌČ╚ų«ķgĄ─┬ōŽĄ┐╔ęįė├╦─┤╬ČÓĒŚ╩Į▒Ē╩Š×ķ╩Į(5), Ųõ┐╔øQŽĄöĄR2×ķ0.9963.
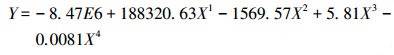
ĪĪĪĪłD 5(Fig. 5)
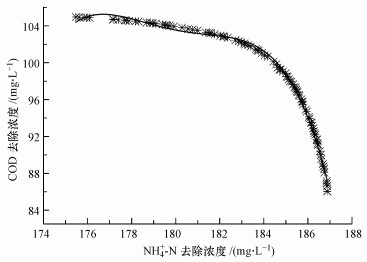
ĪĪĪĪłD 5ā×╗»─Żą═▀\ąąĮY╣¹ Fig. 5 Results of the optimization model
ĪĪĪĪ▒Ē 3Įo│÷┴╦▓┐ĘųParetoūŅā×▀ģĮń³c║═┤╦▀M╦«Śl╝■Ž┬Ą─īŹ“×╩ę│÷╦«šµīŹ£yČ©ųĄ, ī”▒╚─Żą═Įo│÷Ą──ŻöMųĄ┼cīŹ“ךµīŹųĄ, ā╔š▀▓Ņäe▓╗┤¾, ▒Ē├„▒Š╬─╦∙Į©┴óĄ─ČÓ─┐ś╦ā×╗»─Żą═▌^×ķ┐╔┐┐, ─▄ē“Ą├ĄĮūŅā×ĮŌ╝».łD 6Įo│÷┴╦─┐ś╦Ą³┤·▀^│╠ųą├┐ę╗┤·▀M╦«NH4+-NĪóNO2--NĪóCOD║═pHģóöĄĄ─Ęų▓╝Ūķør, Å─łDųą┐╔ęį┐┤│÷, ▀M╦«CODūā╗»▓╗┤¾, ŲõųĄ▒Ż│ųį┌106 mgĪżL-1ū¾ėę, ▀M╦«pHĘų▓╝ė┌7.3~7.5ų«ķg, ▀M╦«NH4+-N┼cNO2--NŠ∙ä“Ęų▓╝ė┌280~320 mgĪżL-1║═210~320 mgĪżL-1ų«ķg;▀Mę╗▓ĮĘų╬÷▀M╦«NH4+-N/NO2--N┼c│÷╦«NH4+-N╚ź│²ØŌČ╚ų«ķgĄ─ĻPŽĄ(łD 7a), ░l¼FļSų°│÷╦«NH4+-N╚ź│²ØŌČ╚į÷┤¾, NH4+-N/NO2--Nė╔0.95į÷┤¾ĄĮ1.50, Ųõ▒Ē¼F×ķ▀M╦«NH4+-NØŌČ╚į÷┤¾, Č°NO2--NØŌČ╚ĮĄĄ═, ▀@┐╔─▄╩Ūę“×ķĖ▀ØŌČ╚Ą─NO2--NĢ■ęųųŲ╬ó╔·╬’╗Ņąį, ŽÓæ¬Ą─ļm╚╗NH4+-NØŌČ╚╠ß╔², Ą½Ą═pHŽÓæ¬Ą─Ą═ė╬ļx░▒╩╣ģÆč§░▒č§╗»ŽĄĮyĖ³×ķĘĆČ©(Jaroszynski et al., 2011);Ęų╬÷▀M╦«COD/NH4+-N┼c│÷╦«NH4+-N╚ź│²ØŌČ╚ų«ķgĄ─ĻPŽĄ, Å─łDųą┐╔ęį┐┤│÷(łD 7b), ļSų°│÷╦«NH4+-N╚ź│²ØŌČ╚į÷┤¾, COD/ NH4+-Nė╔0.38Ž┬ĮĄĄĮ0.33, ┐╔ęŖꬎļ╩╣ģÆč§░▒č§╗»Ę┤æ¬Ų„Š▀ėą▌^āץ─├ōĄ¬ą¦╣¹, ┐žųŲ▀M╦«COD┼cNH4+-NØŌČ╚▒╚ųĄ╩Ū╩«Ęųųžę¬Ą─.
ĪĪĪĪłD 6 ParetoūŅā×▀ģĮńųąĖ„ūā┴┐Ęų▓╝
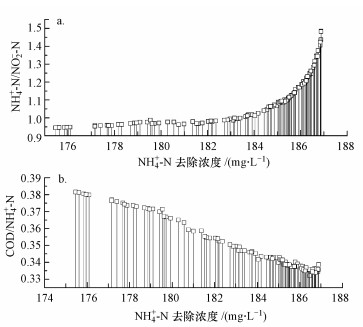
ĪĪĪĪłD 7 NH4+-N/NO2--N (a)ĪóCOD/ NH4+-N (b)┼cNH4+-N╚ź│²ØŌČ╚ĻPŽĄ
ĪĪĪĪ4 ĮYšō(Conclusions)
ĪĪĪĪ1) ═©▀^PCAĮĄŠS▓┘ū„╠Ä└Ē─Żą═▌ö╚ļ┴┐, Ęų╬÷Ė„Ž“┴┐į┌─│ę╗ų„│╔Ęų╔ŽĄ─═Čė░║═╩Ė┴┐ķLČ╚┐╔ų¬, ▀M╦«NH4+-NĪóNO2--NØŌČ╚║═▀M╦«pHČ╝╩Ū╩«Ęųųžę¬Ą─ė░Ēæūā┴┐, ŽÓī”üĒšf, ▀M╦«CODĄ─ė░Ēæ▌^ąĪ.
ĪĪĪĪ2) ═©▀^PCAĮĄŠS▓┘ū„, ┐╔ęį╩╣─Żą═▌ö╚ļūā┴┐ė╔4éĆĮĄ×ķ2éĆ, ╚ź│²╚▀ėÓą┼ŽóĄ─═¼Ģr, ┐╔ęį£p╔┘BPĄ─ėŗ╦Ń┴┐.
ĪĪĪĪ3) ßśī”ģÆč§░▒č§╗»▀^│╠ųąNH4+-N╚ź│²║═COD╚ź│²ļpĒŚā×╗»å¢Ņ}, │╔╣”Į©┴óŲ╗∙ė┌PCA-BPĄ─│÷╦«NH4+-N╚ź│²║═COD╚ź│²ŅA£y─Żą═, ─Żą═£yįćöĄō■┼cīŹļHöĄō■Ą─ŽÓĻPŽĄöĄĘųäe×ķ0.9164║═0.9987, Ūęā╔─Żą═Ą─ŲĮŠ∙ŅA£yš`▓ŅČ╝▒Ż│ųį┌į┌10%ęįā╚.
ĪĪĪĪ4) į┌│÷╦«NH4+-N╚ź│²║═COD╚ź│²ŅA£y─Żą═╔Ž, └¹ė├NSGA-ó“Į©┴ó┴╦ģÆč§░▒č§╗»┼cĘ┤Ž§╗»ģf═¼īŹ¼F═¼▓Į├ōĄ¬│²╠╝ā×╗»─Żą═, ā×╗»ĮY╣¹▒Ē├„, įō─Żą═Įo│÷Ą─ĮŌøQĘĮ░Ėėąą¦┐╔ąą, Ęų╬÷Ė„▀M╦«ģóöĄų«ķgĄ─ĻPŽĄĄ├│÷, ļSų°│÷╦«NH4+-N╚ź│²─▄┴”Ą─╠ß╔², 欫ö╠ßĖ▀▀M╦«NH4+-N/NO2--N║═ĮĄĄ═COD/ NH4+-NĄ─▒╚ųĄĪŻ(üĒį┤Ż║ŁhŠ│┐ŲīWīWł¾ ū„š▀Ż║ųx▒“)

