═┴╚└ųžĮī┘╬█╚ŠĘų╬÷
ųąć°╬█╦«╠Ä└Ē╣ż│╠ŠW ĢrķgŻ║2016-6-13 9:23:46
╬█╦«╠Ä└Ē╝╝ąg | ģRŠ█╚½Ū“Łh▒Ż┴”┴┐Ż¼ĮĄĄ═Ų¾śIų╬╬█│╔▒Š
ĪĪĪĪ1 ę²čį
ĪĪĪĪģ^ė“═┴╚└ųžĮī┘╬█╚Šįuār╩Ū═┴╚└ŁhŠ│蹊┐Ą─║═╬█╚ŠĘ└ų╬Ą─ųžę¬╗∙ĄA─┐Ū░ī”ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚Ą─įuārĘĮĘ©ęčėą║▄ČÓ蹊┐Ż¼╚ńå╬ę“ūėųĖöĄĘ©ĪóĄž└█ĘeųĖöĄĘ©Īó╔·æB’LļUŽĄöĄĘ©Ą╚║åå╬ųĖöĄĘ©Ż¼ā╚├Ę┴_ųĖöĄĪó╝ėÖÓŠC║ŽųĖöĄĪó╔·æB’LļUŠC║ŽŽĄöĄĄ╚ŠC║ŽųĖöĄĘ©Ż¼▀@ą®įuār─Żą═į┌═┴╚└ųžĮī┘įuārŅIė“Ą├ĄĮ┴╦ÅVĘ║æ¬ė├.×ķ┴╦ĮŌøQé„ĮyĄ─ųĖöĄĘ©įuārļyęį├Ķ╩÷═┴╚└ųžĮī┘╬█╚ŠĄ─▓╗┤_Č©ąįå¢Ņ}Ż¼─Ż║²öĄīWĘĮĘ©į┌═┴╚└ųžĮī┘╬█╚ŠįuārŅIė“Ą├ĄĮÅVĘ║Ą─æ¬ė├.║╦├▄Č╚╣└ėŗĘ©▓╗ī”öĄō■Ą─Ęų▓╝ą╬╩Į▀MąąŅAŽ╚Ą─╝┘įOŻ¼Š▀ėąĖ³ÅVĘ║Ą─▀mė├ąįŻ¼Ą½─┐Ū░║╦├▄Č╚╣└ėŗ─Żą═į┌ūį╚╗┐ŲīW╔ŽĄ─æ¬ė├▓╗ČÓŻ¼ų„ę¬╩Ū╝»ųąį┌╔ńĢ■ĪóĮøØ·ęį╝░ßt╦ÄĄ╚ŅIė“.
ĪĪĪĪ▓╗═¼įuārĘĮĘ©Ė„ėąæ¬ė├╠ž³cŻ¼įuārĘĮĘ©ų„ę¬╩ŪšŲ╬ščąŠ┐ģ^ė“┐é¾w╬█╚Š│╠Č╚Ż¼Ą½║▄╔┘ėąīWš▀ī”▓╗═¼ĘĮĘ©įuārĮY╣¹▀MąąŽĄĮyĄ─┐éĮY┼c▒╚▌^Ż¼╝┤╩╣ėąę▓āHāH═Ż┴¶į┌└Ēšō╔ŽĄ─ĮķĮBŻ¼╚▒ʔȩ┴┐╠ĮėæĖ„ĘĮĘ©įuārĮY╣¹Ą─▓Ņ«É(ĘČ╦®Ž▓Ą╚Ż¼2010;╣∙ą”ą”Ą╚Ż¼2011).ę“┤╦Ż¼▒Š╬─ęįĮøØ·┐ņ╦┘░lš╣Ą─└ź╔Į╩ą×ķ└²Ż¼▓╔ė├║åå╬öĄ└ĒĮyėŗĪóš²æB─Ż║²öĄĘ©║═║╦├▄Č╚╣└ėŗĘ©ī”蹊┐ģ^═┴╚└ųžĮī┘┐é¾w╬█╚Š│╠Č╚▀MąąįuārŻ¼Å─įuār▒ŃĮ▌ąįĪóĮY╣¹Ą─£╩┤_Č╚┼c╚½├µąįĘĮ├µĮę╩ŠĖ„ĘĮĘ©Ą─▓Ņ«É.
ĪĪĪĪ2 蹊┐ģ^Ė┼ør
ĪĪĪĪ└ź╔Į╩ą╬╗ė┌ĮŁ╠K╩Ī¢|─Ž▓┐Ż¼╔Ž║Ż║═╠Kų▌ų«ķgŻ¼Ąž╠Ä¢|Įø120ĪŃ48Īõ21ĪÕ~121ĪŃ09Īõ04ĪÕEŻ¼▒▒ŠĢ31ĪŃ06Īõ34ĪÕ~ 31ĪŃ32Īõ36ĪÕNŻ¼╩Ū╔Ž║ŻĮøØ·╚”ųžę¬Ą─ą┬┼d╣ż╔╠│Ū╩ąŻ¼2013─Ļ╚╦Š∙GDP▀_2.89╚f├└į¬Ż¼▀B└m9─Ļ▒╗įu×ķ╚½ć°░┘ÅŖ┐h╩ąų«╩ū.└ź╔Į╩ąī┘ė┌Ąõą═Ą─▒▒üå¤ßĦ╝Š’LÜŌ║“Ż¼─ĻŲĮŠ∙ÜŌ£ž17.6 ĪµŻ¼─ĻŲĮŠ∙ĮĄ╦«┴┐1200.4 mmŻ¼╚½╩ą═┴╚└Ęų×ķ╦«ĄŠ═┴Īó│▒═┴ĪóšėØ╔═┴Īó³Sūž╚└4éĆ═┴ŅÉŻ¼╦«ĄŠ═┴į┌Ė„ŅÉ═┴╚└┐é├µĘeųąš╝▒╚ūŅĖ▀Ż¼▀_93.8%.
ĪĪĪĪ3 öĄō■üĒį┤║═ĘĮĘ©
ĪĪĪĪ3.1 öĄō■üĒį┤
ĪĪĪĪ蹊┐öĄō■×ķ2 kmĪ┴2 kmŠWĖ±Ą─═┴╚└▓╔śė£yįćöĄō■Ż¼īó蹊┐ģ^äØĘų│╔2 kmĪ┴2 kmĄ─ŠWĖ±Ż¼├┐éĆŠWĖ±ū„×ķę╗éĆ▓╔śė³cŻ¼ī”ė┌ģ^ė“▀ģĮń╔ŽĄ─ŲŲ╦ķŠWĖ±░┤šš╦─╔ß╬Õ╚ļüĒ╠Ä└ĒŻ¼╣▓▀x╚Ī232éĆśė³c.░┤šš5³c╗ņ║Ž▓╔śėĘ©▓╔╝»0~20 cm▒Ēīė═┴╚└śėŲĘŻ¼╦─ĘųĘ©╚ĪĘų╬÷śėŲĘ╝s1.5 kg.śėŲĘĮøūį╚╗’LĖ╔Ż¼╠¶│²╩»Ą[║═ų▓╬’Üł¾wŻ¼čą─ź▀^100─┐║YŻ¼▓ó│õĘų╗ņä“ęį┤²ė├.

ĪĪĪĪłD1 ▓╔śė³cĘų▓╝łD
ĪĪĪĪ▒Š╬─é╚ųžčąŠ┐▓╗═¼ĘĮĘ©Ž┬═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuārĮY╣¹Ą─▓Ņ«ÉŻ¼▌^═┴╚└ųžĮī┘ŠC║Ž╬█╚Šįu╣└Č°čįŻ¼å╬į¬╦žįu╣└┐╔ęį├Ō╚źŠC║Ž╬█╚ŠĄ─╝ėÖÓŪ¾║═Ż¼─▄£p╔┘▓╗═¼ÖÓųžī”ĮY╣¹Ą─Ė╔ö_.ęčėąčąŠ┐▒Ē├„Ż║ū„×ķ╦«ŠWĄžģ^Ą─└ź╔Į╩ą═┴╚└As║¼┴┐ŽÓī”▓╗Ė▀Ż¼┐šķgĘų«É│╠Č╚ę▓▌^ąĪ;Cd║¼┴┐ŽÓī”▌^Ė▀Ż¼┐šķgĘų«É│╠Č╚ę▓▌^┤¾(╚f╝tėčĄ╚Ż¼2006;ńŖĢį╠mĄ╚Ż¼2008).▀@ā╔ĘNį¬╦žŠ▀ėą▌^ÅŖĄ─┤·▒ĒąįŻ¼─▄į┌╬█╚Šįu╣└ĮY╣¹ųąą╬│╔▌^×ķ§r├„Ą─ī”▒╚Ż¼ę“┤╦Ż¼▒Š╬─▀x╚ĪAs║═Cd×ķ┤·▒Ēį¬╦ž▀MąąčąŠ┐.Cd▓╔ė├Ęųäe╝ė╚ļØŌ¹}╦ßĪóØŌŽ§╦ßį┌150 ĪµĄ─ėą┐ūļŖ¤ß░Õ╔Ž╝ė¤ßĘ┤æ¬Īóį┘╝ė╚ļHF-HNO3-HClO4ų├ė┌200 Īµėą┐ūļŖ¤ß░Õ╔Ž╝ė¤ßŽ¹ĮŌ║¾Ż¼▓╔ė├ICP-MSĘ©£yČ©;As▓╔ė├1 Ī├ 1Ą─═§╦«Ęą╦«įĪŽ¹ĮŌ║¾ė├▀ĆįŁÜŌ╗»-įŁūė¤╔╣Ō╣ŌūVĘ©▀Mąą£yČ©.
ĪĪĪĪ3.2 蹊┐ĘĮĘ©
ĪĪĪĪ3.2.1 Ąž└█ĘeųĖöĄĘ©
ĪĪĪĪĄž└█ĘeųĖöĄĘ©═©│ŻĘQ×ķMullerųĖöĄŻ¼─▄║▄║├ĄžĘ┤ė│ūį╚╗ūā╗»┼c╚╦×ķ╗Ņäėę“╦žī”ųžĮī┘Ęų▓╝ĦüĒĄ─ė░ĒæŻ¼╦³ęį蹊┐ģ^ųžĮī┘║¼┴┐▒│Š░ųĄ×ķś╦£╩Ż¼╩Ūįuārģ^ė“ųžĮī┘╬█╚ŠĄ─ųžę¬╬█╚ŠųĖöĄ.Š▀¾w╣½╩Į╚ńŽ┬Ż║
ĪĪĪĪ╩ĮųąŻ¼Ci×ķ═┴╚└ųžĮī┘į¬╦žiĄ─īŹ£y║¼┴┐(mg Īż kg-1); Bi×ķį¬╦žiĄ─ģ^ė“▒│Š░ųĄ(mg Īż kg-1);k×ķą▐š²ŽĄöĄŻ¼ę╗░Ń╚Ī×ķ1.5.Ė∙ō■Ąž└█ĘeųĖöĄųĄIgeoŻ¼īó═┴╚└ųžĮī┘╬█╚Š│╠Č╚äØĘų×ķ5éĆĄ╚╝ē.ŲõųąIgeoĪ▄0Ģr×ķ0╝ēŻ¼ŪÕØŹ;03Ģr×ķ4╝ēŻ¼ć└ųž╬█╚Š.
ĪĪĪĪ▒Š╬─Ą─ųžĮī┘║¼┴┐▒│Š░ųĄ▓╔ė├æ¬ė├ÅVĘ║Ą─ĪČųąć°═┴╚└į¬╦ž▒│Š░ųĄĪĘ(ć°╝ęŁhŠ│▒ŻūoŠų║═ųąć°ŁhŠ│▒O£y┐隊Ż¼1990)ųą╚½ć°Ė„╩ĪĘ▌═┴╚└╬ó┴┐Įī┘į¬╦ž▒│Š░ųĄ.
ĪĪĪĪ3.2.2 š²æB─Ż║²öĄ─Żą═
ĪĪĪĪ─Ż║²öĄĘ©╩Ūßśī”ģ^ė“═┴╚└ųžĮī┘╬█╚ŠĄ──Ż║²Īó▓╗┤_Č©ąį╠žš„╦∙▀MąąĄ─įuārŻ¼─▄Ė³×ķ╚½├µĄžĘ┤ė│ųžĮī┘╬█╚Š│╠Č╚ą┼ŽóŻ¼┐╔ĮŌøQé„ĮyĄ─ųĖöĄĘ©įuārļyęį├Ķ╩÷═┴╚└ųžĮī┘╬█╚ŠĄ─▓╗┤_Č©ąįå¢Ņ}.─Ż║²öĄ─Żą═Ą─║╦ą─╩ŪśŗĮ©ļ`ī┘Č╚║»öĄŻ¼─┐Ū░ų„ę¬╩Ū▓╔ė├ŠĆąįą╬╩ĮüĒ▀Mąą├Ķ╩÷Ż¼└²╚ń╚²ĮŪ┼c╠▌ą╬─Ż║²öĄĘ©Ż¼▒Š╬─▓╔ė├š²æB─Ż║²öĄįuārĘĮĘ©Ż¼═©▀^Ė┼┬╩├▄Č╚Ū·ŠĆķgĮėĘ┤ė│ļ`ī┘Č╚┤¾ąĪ(ęūĻ╗ĢFĄ╚Ż¼2013).
ĪĪĪĪįOšōė“×ķR+(š²īŹöĄė“)╔ŽĄ─ę╗éĆ─Ż║²öĄŻ¼Č©┴xA~Ą─ļ`ī┘║»öĄ×ķŻ║”╠ A(x):RĪ·$0Ż¼1]Ż¼xĪ╩RŻ¼š²æB─Ż║²öĄļ`ī┘║»öĄ”╠A(x)▒Ē╩Š×ķŻ║
ĪĪĪĪ
╩ĮųąŻ¼”╠×ķīŹ£yöĄō■Ą─ŲĮŠ∙ųĄŻ¼”ę×ķīŹ£yöĄō■Ą─ś╦£╩▓Ņ.A~ū„×ķę╗éĆ─Ż║²öĄāHŠ▀ėąĖ┼─Ņ╔ŽĄ─ęŌ┴xŻ¼¤oĘ©ų▒Įėģó┼c▀\╦Ń.īŹļHæ¬ė├ĢrŻ¼ę╗░Ń═©▀^”┴Ī¬Įž╝»īó─Ż║²öĄ▐D╗»×ķę╗Č©ų├ą┼Č╚╦«ŲĮĄ─ģ^ķgöĄ.”┴Ī¬Įž╝»Č©┴x╚ńŽ┬Ż║
~Ī╩F(U)Ż¼ī”ė┌╚╬ęŌ”┴Ī╩0Ż¼]Ż¼ėøŻ║(A~)”┴”ż A”┴”ż {”╠|(”╠)Ī▌a}
ę╗░ŃČ°čįŻ¼”┴╚Ī0.9╩ŪŲš▒ķ┐╔ęįĮė╩▄Ą─ų├ą┼Č╚╦«ŲĮ(└Ņ╚ńųęŻ¼2011)Ż¼Ė∙ō■╩Į(2)ęūŪ¾Ą├ģ^ķgöĄA”┴Ż║
ĪĪĪĪ╚╗║¾ėŗ╦Ńę╗Č©ų├ą┼Č╚╦«ŲĮŽ┬ģ^ė“ųžĮī┘Ą─Ąž└█ĘeųĖöĄģ^ķgöĄŻ¼ī”Ąž└█ĘeųĖöĄģ^ķgöĄ▀MąąĖ„╬█╚ŠĄ╚╝ēĄ─ļ`ī┘Č╚ėŗ╦ŃŻ¼Ė∙ō■ģ^ķgöĄī”Ė„╬█╚Š│╠Č╚Ą╚╝ēĄ─ļ`ī┘Č╚Ż¼▀Mąą╝ėÖÓŪ¾║═Ą├│÷įōģ^ķgöĄĄ─ųžĮī┘╬█╚Š│╠Č╚.ī”ė┌╝╚Ą├Ą─š²æBļ`ī┘Č╚Ū·ŠĆŻ¼═©▀^Ū¾╚ĪČ©ĘeĘųĄ─ĘĮ╩ĮüĒ½@╚Ī蹊┐ģ^═┴╚└ųžĮī┘▓╗═¼╬█╚ŠĄ╚╝ēĄ─├µĘeš╝▒╚.
ĪĪĪĪ3.2.3 ║╦├▄Č╚╣└ėŗ─Żą═
ĪĪĪĪ║╦├▄Č╚╣└ėŗū„×ķĘŪģóöĄ╣└ėŗ└ĒšōųąĄ─ę╗éĆĄõą═ĘĮĘ©Ż¼įōĘĮĘ©Ą─╠ž³cį┌ė┌ī”▓╔śė³cöĄō■Ą─Ęų▓╝ą╬╩Į▓╗ū„╚╬║╬╝┘Č©Ż¼āHę└┘ćė┌öĄō■▒Š╔ĒŻ¼╩Ū═Ļ╚½öĄō■“īäėŽ┬Ą─├▄Č╚║»öĄĄ─╣└ėŗ.ę“┤╦į┌═┴╚└ųžĮī┘öĄō■Ą─ą┼Žó═┌Š“╔Žėą║▄ÅŖĄ─▀mė├ąį.
ĪĪĪĪī”ė┌śė▒ŠöĄō■x1Ż¼x2...xnŻ¼║╦├▄Č╚╣└ėŗ╣½╩Į×ķŻ║
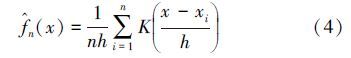
ĪĪĪĪ╩ĮųąŻ¼KĘQ×ķ║╦║»öĄŻ¼n╩Ū┐é¾wśė▒ŠöĄŻ¼h×ķ┤░īÆųĄ╗“╣Ō╗¼ŽĄöĄ.
ĪĪĪĪ║╦║»öĄ×ķĻPė┌y▌Sī”ĘQ▓óŪęŲõĘeĘų×ķ1Ą─Ė┼┬╩├▄Č╚║»öĄŻ¼│Żė├Ą─║╦║»öĄĘNŅÉęŖ▒Ē 1.Ė∙ō■ęį═∙īWš▀Ą─蹊┐Ż¼▓╗═¼║╦║»öĄī”ĮY╣¹Ą─ė░Ēæ▌^ąĪ(╣∙ššŪfĄ╚Ż¼2008)Ż¼▒Š╬─▀xō±æ¬ė├▌^×ķÅVĘ║Ą─Ė▀╦╣║╦║»öĄ▀MąąčąŠ┐.
▒Ē1 │ŻęŖ║╦║»öĄŅÉą═

ĪĪĪĪ┤░īÆī”║╦├▄Č╚╣└ėŗĄ─ĮY╣¹╩«Ęųųžę¬Ż¼╦³Ą─ųĄ╚ń╣¹▀^┤¾Ż¼ät║╦├▄Č╚Ū·ŠĆĢ■▀^ė┌ŲĮ╗¼Ż¼Ę┤ų«Ż¼ätŪ·ŠĆĢ■│÷¼F║▄ć└ųžĄ─õŲX.┤_Č©ę╗éĆ║Ž└ĒĄ─┤░īÆųĄų┴ĻPųžę¬Ż¼ūŅ£╩┤_║═┐ŲīWĄ─ĘĮĘ©╩Ūėŗ╦Ń║╦╣└ėŗ╩ĮĻPė┌šµīŹĖ┼┬╩├▄Č╚║»öĄĄ─Š∙ĘĮš`▓Ņ(MSE)Ż¼Ą½▀@ĘNĘĮĘ©ģs▓╗─▄į┌īŹļH蹊┐ųą▀Mąąæ¬ė├Ż¼ę“×ķŲõė├ĄĮ┴╦Ž╚“×ų¬ūR.ęį▒Š╬─Ą─蹊┐×ķ└²Ż¼╚¶čąŠ┐ģ^ųžĮī┘║¼┴┐Ą─Ė┼┬╩├▄Č╚Ęų▓╝šµīŹųĄęčĮøšŲ╬šŻ¼Š══Ļ╚½ø]ėą▀Mąą║╦╣└ėŗĄ─▒žę¬Ż¼ę“┤╦Ż¼įōĘĮĘ©āHāHŠ▀ėą└Ēšō╔ŽĄ─ęŌ┴x.
ĪĪĪĪį┌▓╗ąĶꬎ╚“×ų¬ūRĄ─ŪķørŽ┬Ż¼Į╗▓µ“×ūCĘ©ī”śė▒ŠöĄį┌100~1000Ą─ĘČć·ā╚┤░īÆĄ─▀x╚ĪŠ½Č╚▌^Ė▀(╚╬£ž▄Ŗ║═╦╬Ž“¢|Ż¼2009)Ż¼Ą½╚▌ęūŽ▌╚ļŠų▓┐ūŅā×╗».×ķ┴╦▒▄├Ō▀@ĘNė░ĒæŻ¼▒Š╬─īóĮ╗▓µ“×ūCĘ©╦∙Ą├┤░īÆųĄ┼cīŹļHæ¬ė├ųąĄ─ę╗éĆĮø“×ųĄ╚ĪŲĮŠ∙Ż¼ū„×ķūŅĮKĄ─┤░īÆųĄ.╣½╩Į(5)×ķĮ╗▓µ“×ūCĘ©▀x╚Ī┤░īÆĄ─╣½╩Į(ģŪŽ▓ų«║═┌w▓®ŠĻŻ¼2009)Ż║╣½╩Į(6)×ķīŹļHæ¬ė├ųą┤_Č©┤░īÆĄ─Įø“×╣½╩ĮŻ¼╣½╩Į(7)×ķūŅĮKĄ─┤░īÆ╣½╩Į.
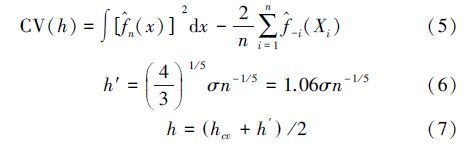
ĪĪĪĪ╩ĮųąŻ¼f^-i(Xi)×ķäh╚źĄ┌iéĆė^£y³cų«║¾Ą├ĄĮĄ─║╦├▄Č╚╣└ėŗ.ūŅā×┤░īÆųĄhcvĄ╚ārė┌╩╣║»öĄųĄCV(h)ūŅąĪ.ī”ė┌ųžĮī┘Ą─║╦├▄Č╚Ū·ŠĆŻ¼ģ^ė“┐é¾w╬█╚Š│╠Č╚ęį╝░Ė„éĆ╬█╚ŠĄ╚╝ē├µĘeĄ─▒╚ųžŻ¼ę▓▀\ė├Č©ĘeĘųüĒŪ¾╚Ī.
ĪĪĪĪ4 ĮY╣¹┼cėæšō
ĪĪĪĪ4.1 蹊┐ģ^═┴╚└ųžĮī┘╬█╚Š│╠Č╚ģóššųĄĄ──ŻöM
ĪĪĪĪ▒Š╬─īó▓╔śė³cöĄō■▀Mąą┐╦└’Ė±▓ÕųĄ║¾╦∙Ą├ĄĮĄ─¢┼Ė±öĄō■ū„×ķģóššųĄŻ¼ļm╚╗įōģóššųĄ▒Š┘|╔Ž╚į┼f╩Ūļx╔óĄ─³cŻ¼ŲõĮyėŗĮY╣¹┼cšµīŹųĄŽÓ▒╚╚į┤µį┌š`▓ŅŻ¼Ą½┐╔ęįģóššįōųĄüĒ£y╦ŃĖ„įuārĘĮĘ©ĮY╣¹Ą─Ų½▓Ņ.
ĪĪĪĪī”¢┼Ė±łD▀MąąöĄō■ĮyėŗĘų╬÷Ż¼┐╔ęįĄ├ĄĮ▒Ē 2Ą─öĄō■ū„×ķįuārĄ─ģóššųĄ.Å─▒Ē 2┐╔ęį┐┤│÷Ż¼ģó┼cĮyėŗĄ─¢┼Ė±łDŽ±į¬ųĄ▀_ĄĮ┴╦50741éĆŻ¼öĄō■┴┐öU┤¾┴╦218▒Č.ĮyėŗĘų╬÷┐╔ų¬Ż¼čąŠ┐ģ^AsĪóCdĄ─ŲĮŠ∙Ąž└█ĘeųĖöĄģóššųĄĘųäe×ķ-0.56Īó0.26Ż¼┐é¾w╬█╚Š│╠Č╚Ęųäe╩ŪŪÕØŹ║═▌pČ╚╬█╚Š.
ĪĪĪĪ▒Ē2 蹊┐ģ^═┴╚└ųžĮī┘Ąž└█ĘeųĖöĄģóššųĄ

ĪĪĪĪ4.2 ╗∙ė┌Ąž└█ĘeųĖöĄĄ─ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuār
ĪĪĪĪ▓╔ė├Ąž└█ĘeųĖöĄĘ©Ż¼═©▀^╚ĪŲĮŠ∙ųĄėŗ╦Ńģ^ė“┐é¾w╬█╚Š│╠Č╚Ż¼į┘░┤ššĖ„éĆśė³cĄ─╬█╚Š│╠Č╚Ą╚╝ē▀Mąą║åå╬ĮyėŗŻ¼Ą├ĄĮĖ„╝ēäe╬█╚Šģ^ė“Ą─├µĘeš╝▒╚.Š▀¾wįuārĮY╣¹ęŖ▒Ē 3.Å─▒Ē 3ĮY╣¹┐╔ęį┐┤│÷Ż¼▀\ė├å╬╝āĄž└█ĘeųĖöĄ▀MąąįuārŲ½▓ŅĢ■▌^┤¾Ż¼ģ^ė“ŲĮŠ∙Ąž└█ĘeųĖöĄŽÓī”ė┌ģóššųĄĄ─Ų½▓ŅĘųäe×ķ14.3%Īó19.2%.Asį┌š¹éĆ蹊┐ģ^Ą─ŲĮŠ∙╬█╚Š│╠Č╚▌^Ą═Ż¼┐é¾w╬█╚Š│╠Č╚įuārĮY╣¹Ų½Ą═Ż¼Ė„╬█╚ŠĄ╚╝ē├µĘeš╝▒╚Ą─Ų½▓Ņ▓╗┤¾;Ė„╬█╚Šģ^ė“├µĘeš╝▒╚Ą─Ų½▓Ņį┌Cdųą¾w¼F▌^×ķ├„’@Ż¼ųžĮī┘╬█╚ŠįuārĮY╣¹Ų½Ė▀.┐é¾w╔ŽüĒ┐┤Ż¼▀\ė├║åå╬Įyėŗ╦∙Ą├ĄĮĄ─ĮY╣¹Ų½▓Ņ▒╚▌^┤¾Ż¼╚ń║╬į┌įuār─Żą═╔Ž▀Mąąę╗ą®Ė─▀Męį£p╔┘▀@ĘNŲ½▓Ņ║▄ėą▒žę¬.
ĪĪĪĪ▒Ē3 ╗∙ė┌║åå╬Ąž└█ĘeĮyėŗĘ©Ą─蹊┐ģ^═┴╚└AsĪóCd╬█╚Š│╠Č╚įuārĮY╣¹

ĪĪĪĪ4.3 ╗∙ė┌─Ż║²öĄĘ©Ą─ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuār 4.3.1 įuārĄ─▀^│╠┼cĮY╣¹
ĪĪĪĪ蹊┐ģ^ųžĮī┘Ą─š²æB╗“ī”öĄš²æBĘų▓╝╠žš„╩Ū▀\ė├š²æB─Ż║²öĄĘ©įuārĄ─Ū░╠ߌl╝■║═╗∙ĄAŻ¼▀MąąK-SÖz“ׯ¼Ą├ĄĮCdĄ─sigųĄ×ķ0.062Ż¼═©▀^ī”As▀Mąąā╔┤╬ī”öĄ▐DōQŻ¼ŲõsigųĄ×ķ0.107Ż¼CdĪóAsį┌0.05Ą─’@ų°╦«ŲĮŽ┬ĘųäeĘ■Å─š²æBĪóī”öĄš²æBĘų▓╝Ż¼╝┤┐╔ī”蹊┐ģ^▀Mąą╗∙ė┌š²æB─Ż║²öĄ─Żą═Ą─AsĪóCd╬█╚Šįuār.
ĪĪĪĪ▒Ē4 ╗∙ė┌š²æB─Ż║²öĄĄ─蹊┐ģ^═┴╚└AsĪóCd╬█╚Š│╠Č╚įuārĮY╣¹

ĪĪĪĪCdėŗ╦ŃĄ├ĄĮś╦£╩╗»║¾ŪÕØŹĪó▌pČ╚║═ųąČ╚╬█╚Š├µĘeš╝▒╚Ęųäe╩Ū23.02%Īó71.96%Īó5.02%Ż¼Ų½▓Ņ×ķ+5.10%Īó-4.20%Īó-0.90%.┼cģóššųĄŽÓ▒╚Ż¼ŪÕØŹģ^ė“├µĘeš╝▒╚ėą╦∙╠ßĖ▀Ż¼Č°▌pČ╚║═ųąČ╚╬█╚ŠĄ─ģ^ė“├µĘeš╝▒╚ėą▓╗═¼Ę∙Č╚Ą─Ž┬ĮĄŻ¼┐é¾wįuārĮY╣¹ėąę╗Č©│╠Č╚Ų½Ą═.Asėŗ╦ŃĮY╣¹×ķÜwę╗╗»║¾ŪÕØŹĪó▌pČ╚║═ųąČ╚╬█╚Š├µĘeš╝▒╚Ęųäe×ķ99.81%Īó0.19%Īó0Ż¼ŪÕØŹĪóŪÕČ╚╬█╚ŠĄ─Ų½▓ŅĘųäe×ķ+0.11%Īó-0.11%.ĮY║Ž▒Ē 3Ą─ĮY╣¹Ż¼įōš╝▒╚ĮY╣¹Ė³╝ėĮėĮ³ė┌ģóššųĄŻ¼šf├„ī”ė┌š╝▒╚╩«Ęų╬óąĪĄ─▌pČ╚╬█╚Š├µĘeš╝▒╚Ż¼š²æB─Ż║²öĄ─Żą═╚įėąę╗Č©Ą─ūRäe╣”─▄.
ĪĪĪĪ4.3.2 ┼cé„ĮyĄ─ŠĆąį─Żą═įuārĮY╣¹Ą─Č©┴┐▒╚▌^
ĪĪĪĪ╗∙ė┌─Ż║²öĄ─Żą═Ą─═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuārŻ¼Ė³ČÓīWš▀▀xō±Ą─╩ŪŠĆąį─Ż║²öĄŻ¼ŲõųąĄ─Ąõą═┤·▒Ē╩Ū╚²ĮŪ─Ż║²öĄŻ¼▒Š╬─▀\ė├╚²ĮŪ─Ż║²öĄ▀MąąčąŠ┐ģ^╬█╚Š│╠Č╚įuārŻ¼▓óīóŲõįuārĮY╣¹┼cš²æB─Ż║²öĄĄ─ĮY╣¹▀MąąČ©┴┐▒╚▌^.╚²ĮŪ─Ż║²öĄĄ─įŁ└ĒĪó╣½╩Į┐╔ģóęŖŽÓĻP╬─½I(└Ņ’wĄ╚Ż¼2012)Ż¼Įž╝»”┴╚į▀xō±0.9Ż¼ėŗ╦ŃĮY╣¹ęŖ▒Ē 5.
ĪĪĪĪ▒Ē5 ╗∙ė┌╚²ĮŪ─Ż║²öĄĄ─蹊┐ģ^═┴╚└AsĪóCd╬█╚Š│╠Č╚įuārĮY╣¹

ĪĪĪĪÅ─▒Ē 5┐╔ęį┐┤│÷Ż¼┼cš²æBą═─Ż║²öĄŽÓ▒╚Ż¼╚²ĮŪ─Ż║²öĄĄ──Ż║²Ąž└█ĘeųĖöĄģ^ķg░l╔·┴╦š²Ž“Ų½ęŲŻ¼╩╣Ą├įuārĄž└█ĘeųĖöĄ┤¾ė┌š²æB─Żą═.ĮY║ŽģóššųĄ┐╔ų¬Ż¼▀@ĘNš²Ž“Ų½ęŲ╩╣AsĄ─Ų½▓Ņ£pąĪĄĮ10.54%Ż¼Ą½╩╣CdĄ─Ų½▓Ņ┤¾Ę∙į÷╝ėĄĮ52.42%Ż¼’@╩Š│÷ŠĆąį─Ż║²öĄĄ─įuārĮY╣¹Š▀ėą▌^ÅŖĄ─▓©äėąį.═¼ĢrŻ¼Å─Ė„Ą╚╝ē╬█╚Šģ^ė“š╝▒╚┐┤│÷Ż¼╚²ĮŪ─Ż║²öĄĢ■╩╣ģ^ķgųĄĘČć·ėą╦∙┐sąĪ.┼cģóššųĄĄ─Ė„Ą╚╝ē╬█╚Š├µĘeš╝▒╚ŽÓ▒╚Ż¼AsĄ─▌pČ╚╬█╚Šģ^ė“š╝▒╚£pąĪŻ¼Č°ŪÕØŹģ^ė“š╝▒╚į÷┤¾;CdĄ─ŪÕØŹģ^ė“║═ųąČ╚╬█╚Šģ^ė“š╝▒╚▀Mę╗▓Į£pąĪŻ¼Č°▌pČ╚╬█╚Šģ^ė“š╝▒╚į÷┤¾Ż¼Å─Č°╩╣Ųõ╬█╚Š▒╚ųžėą╦∙╠ßĖ▀.ę“┤╦Ż¼╚²ĮŪ─Ż║²öĄĄ─įuārĮY╣¹▌^▓Ņ.
ĪĪĪĪ4.4 ╗∙ė┌║╦├▄Č╚╣└ėŗĘ©Ą─ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuār
ĪĪĪĪī”║╦╣└ėŗ╩Į└LłDĄ├ĄĮAsĪóCd║¼┴┐Ą─Ė┼┬╩├▄Č╚Ū·ŠĆ(łD 2)Ż¼Å─Ū·ŠĆą╬ĀŅ┐╔ų¬Ż¼As║¼┴┐Ą─Ė┼┬╩├▄Č╚┤_īŹ│╩¼Fę╗Č©│╠Č╚Ą─š²Ų½æBŻ¼Ė┼┬╩ūŅĖ▀ųĄ│÷¼Fį┌7.2 mg Īż kg-1Ż¼į┌Ųõėęé╚Ą─ūŅ┤¾ųĄ▀_ĄĮ┴╦12 mg Īż kg-1ū¾ėęŻ¼Č°ū¾é╚į┌5.5 mg Īż kg-1ų«Ž┬Š═│÷¼FÄū┬╩╗∙▒Š×ķ0.ėŗ╦Ń║¾Ą├ĄĮ蹊┐ģ^AsĄž└█ĘeųĖöĄŲĮŠ∙ųĄ×ķ-0.62Ż¼Ąž└█ĘeųĖöĄĄ─ĘĮ▓Ņ×ķ0.24Ż¼šf├„║╦├▄Č╚╣└ėŗĘ©─▄ī”ģ^ė“As┐é¾w╬█╚Š│╠Č╚Ą─£╩┤_Č╚įu╣└ĘĮ├µėąę╗Č©╠ßĖ▀Ż¼▓óŪę▀\ė├║╦├▄Č╚╣└ėŗ║¾Ą─öĄō■Ą─ś╦£╩▓Ņę▓┼cģóššųĄę╗ų┬Ż¼Ę┤ė│┴╦įu╣└ĮY╣¹▌^×ķĘĆČ©┐╔┐┐.ĮėŽ┬üĒį┘Ė∙ō■║╦├▄Č╚╣└ėŗŪ·ŠĆī”AsĖ„éĆ╬█╚Š│╠Č╚Ą─├µĘe▒╚ųž▀Mąąėŗ╦Ń.ėŗ╦ŃĮY╣¹×ķŻ║ŪÕØŹģ^ė“╬█╚Š▒╚ųž×ķ99.87%Ż¼▌pČ╚╬█╚Šģ^ė“Ą─▒╚ųž╩Ū0.13%.Ė„╝ē╬█╚Šģ^ė“▒╚ųž┼c─Ż║²öĄĘ©ŽÓ▒╚ŅÉ╦ŲŻ¼Č°║╦╣└ėŗĘ©▌pČ╚╬█╚Šģ^ė“Ą─įu╣└▒╚ųž╔įĄ═Ż¼Ą½ę▓─▄▌^├¶ĖąĄ─’@╩Šš╝▒╚║▄ąĪĄ─▌pČ╚╬█╚Šģ^ė“.
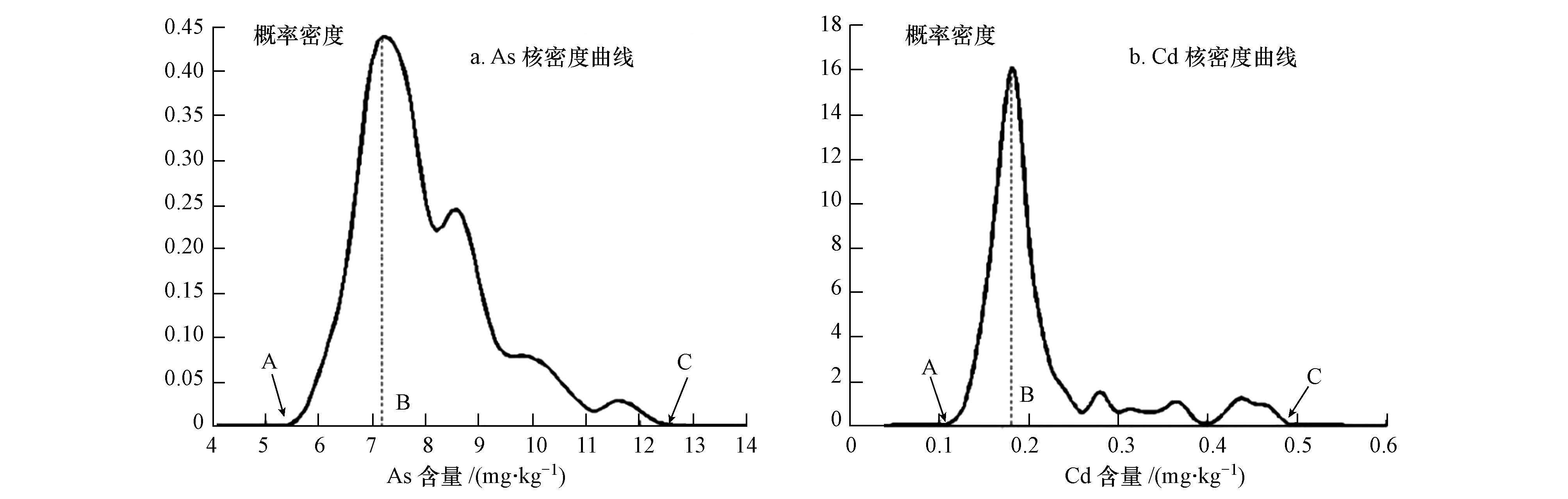
ĪĪĪĪłD2 AsĪóCd║¼┴┐║╦├▄Č╚╣└ėŗŪ·ŠĆ
ĪĪĪĪCdę▓┤µį┌ę╗Č©│╠Č╚Ą─š²Ų½æBŻ¼║¼┴┐ųĄĮ^┤¾▓┐ĘųĘų▓╝į┌0.1~0.25 mg Īż kg-1Ż¼ŲõųąĖ┼┬╩├▄Č╚ūŅĖ▀Ą─ųĄį┌1.8 mg Īż kg-1ū¾ėę.ŽÓ▌^ė┌AsŻ¼Cdį¬╦žĄ─Ū·ŠĆĘÕČ╚ę▓║▄┤¾Ż¼║¼┴┐ųĄį┌0.01 mg Īż kg-1ų«Ū░│÷¼FŅl┬╩╗∙▒Š×ķ0Ż¼Å─0.1Ī½0.2čĖ╦┘╔Ž╔²ų┴ūŅĖ▀³cŻ¼į┘Å─0.2Ī½0.26¾EĮĄų┴║▄Ą═Ą─Ė┼┬╩├▄Č╚ųĄŻ¼▀@║═Asį¬╦žĄ─ļA╠▌╩ĮŽ┬ĮĄėą╦∙▓╗═¼.0.3~0.5 mg Īż kg-1Ė▀║¼┴┐ųĄģ^ķgėąć└ųž═Ž╬▓¼FŽ¾Ż¼įōģ^ķgĖ┼┬╩├▄Č╚ųĄŠ∙║▄Ą═Ż¼▀@ėą┐╔─▄╩Ū▓┐Ęųģ^ė“Ą─╚╦×ķ╬█╚Šįņ│╔.ī”CdĄ─┐é¾w╬█╚Š╦«ŲĮ▀Mąąėŗ╦ŃŻ¼Ą├ĄĮ蹊┐ģ^CdĄž└█ĘeųĖöĄŲĮŠ∙ųĄ×ķ0.30Ż¼Ąž└█ĘeųĖöĄĄ─ĘĮ▓Ņ×ķ0.36.ūŅ║¾ī”Ė„éĆ╬█╚Š╝ēäeĄ─├µĘeš╝▒╚▀MąąĮyėŗŻ¼ŪÕØŹģ^ė“š╝▒╚18.40%Ż¼▌pČ╚╬█╚Šģ^ė“š╝▒╚×ķ70.96%Ż¼ųąČ╚╬█╚Šģ^ė“š╝▒╚10.64%.┼cģóššųĄŽÓ▒╚Ż¼▌pČ╚┼cųąČ╚╬█╚Šģ^ė“├µĘeėą5%ū¾ėęĄ─Ų½▓ŅŻ¼▀@┐╔ęįĮŌßī×ķ║╦╣└ėŗ─Żą═ī”ŽĪ╔┘ųĄĄ─ę╗ĘN├¶ĖąąįŻ¼╝┤CdŪ·ŠĆųąģ^ķg$0.3~0.5]Ą─³c╬╗ŽĪ╔┘Ż¼═©▀^įu╣└Ż¼├┐éĆ³c╬╗Ą─│÷¼FČ╝Ģ■╩╣ŲõĖĮĮ³ųĄĄ─│÷¼FÄū┬╩į÷╝ėŻ¼Ę┤ė│į┌Ė┼┬╩├▄Č╚Ū·ŠĆ╔ŽŻ¼Š═╩Ū▀B└m▓╗ķgöÓĄ─═Ž╬▓¼FŽ¾.
ĪĪĪĪ4.5 ▓╗═¼įuārĘĮĘ©Ž┬ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚Ą─ŠC║Ž▒╚▌^
ĪĪĪĪ▒Š╬─▓╔ė├▓╗═¼ĘĮĘ©ī”蹊┐ģ^AsĪóCdā╔ĘN═┴╚└ųžĮī┘į¬╦žĄ─╬█╚Š│╠Č╚▀Mąą┴╦╬█╚Šįuār.ęįĄž└█ĘeųĖöĄ×ķ╬█╚ŠųĖöĄŻ¼Ęųäe▓╔ė├┴╦║åå╬öĄ└ĒĮyėŗĪó─Ż║²öĄĘ©ęį╝░║╦├▄Č╚╣└ėŗĘĮĘ©▀Mąą┴╦įuār.3ĘNĘĮĘ©Å─įuār▒ŃĮ▌ąį╔Ž╩Ūė╔ęūĄĮļyĄ─Ż¼Ą½▀\ė├Ė³×ķÅ═ļsĄ──Żą═Ģ■╠ßĖ▀įuārĮY╣¹Ą─£╩┤_Č╚╗“╚½├µąį.ŽÓĻPįuārĮY╣¹ęŖłD 3.
ĪĪĪĪłD3(Fig.3)
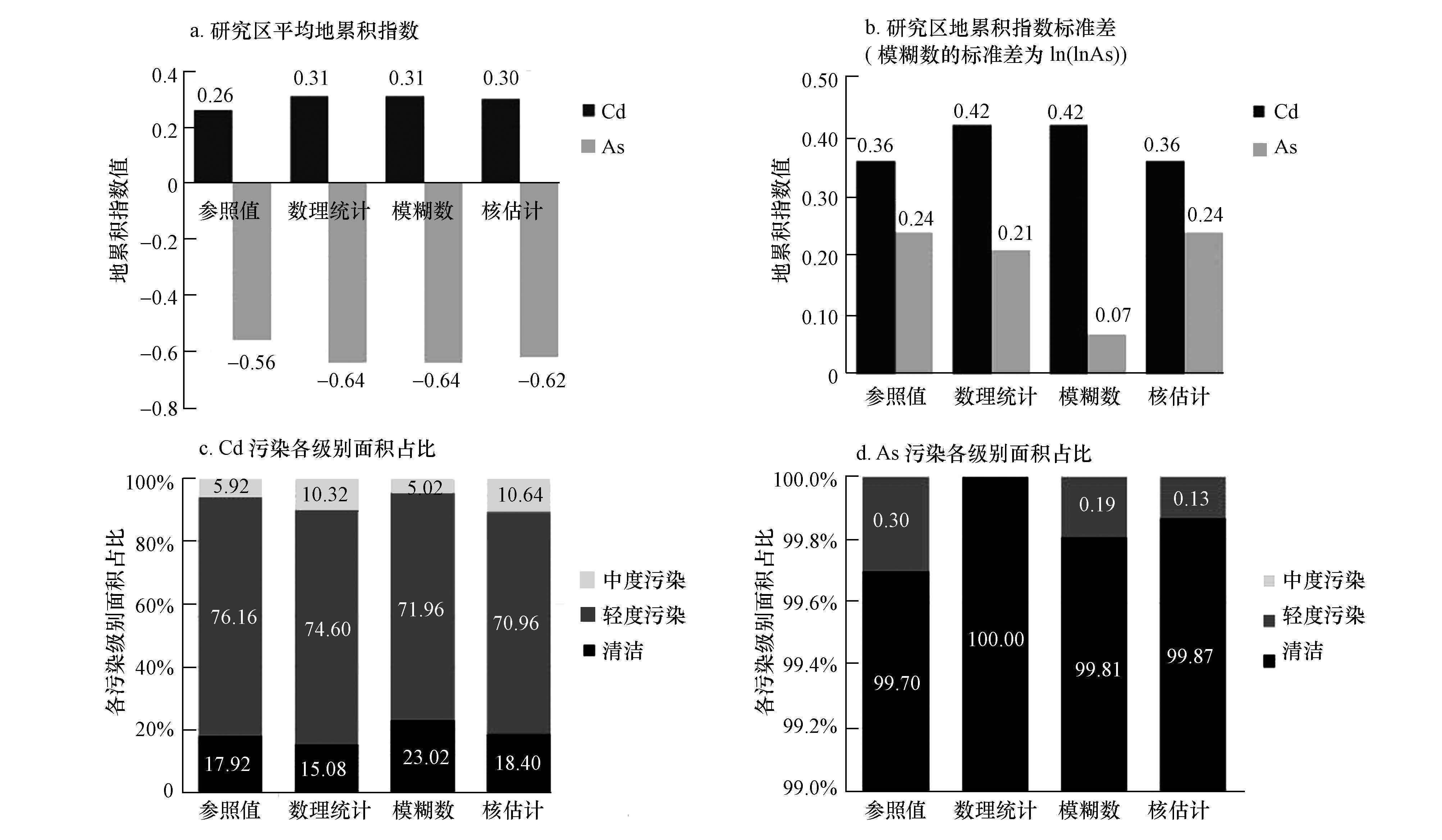
ĪĪĪĪłD3 AsĪóCd▓╗═¼įuārĘĮĘ©ĮY╣¹Ą─ŠC║Ž▒╚▌^
ĪĪĪĪÅ─║åå╬öĄ└ĒĮyėŗ╔ŽüĒšfŻ¼įu╣└Ą─ĮY╣¹▌^×ķ┴╝║├Ż¼£╩┤_Č╚║═ģóššųĄŽÓ▓Ņ▓╗┤¾Ż¼Ą½╩Ūī”Ė„╬█╚ŠĄ╚╝ē├µĘeš╝▒╚Ą─£yČ╚▓╗ē“£╩┤_Ż¼Ģ■▀z┬®čąŠ┐ģ^ė“Ęų▓╝śO╔┘Ą─╬█╚ŠĄ╚╝ē├µĘeš╝▒╚Ż¼▀@ĘNŪķørį┌ī”Asį¬╦žĖ„╬█╚Š╝ēäeĄ─├µĘe▒╚ųž£y╦Ńųąėą╦∙¾w¼FŻ¼╝┤▀z┬®┴╦├µĘeš╝▒╚śO╔┘┴┐Ą─▌pČ╚╬█╚Šģ^ė“.Č°▀\ė├─Ż║²öĄ┼c║╦╣└ėŗ─Żą═▀Mąąįu╣└Š═─▄į┌ę╗Č©│╠Č╚╔Ž▒▄├Ō┴╦▀@éĆå¢Ņ}.
ĪĪĪĪ─Ż║²öĄ─Żą═┼c║åå╬öĄ└ĒĮyėŗĄ─ĮY╣¹ę╗ų┬Ż¼įŁę“į┌ė┌─Żą═Ą─ā╔éĆųžę¬ģóöĄĪ¬Ī¬Š∙ųĄ┼cś╦£╩▓ŅŠ═╩Ū╗∙ė┌śė▒ŠöĄō■Ż¼╣╩▓╗─▄╠ßĖ▀ī”┐é¾w╬█╚Š│╠Č╚įu╣└Ą─£╩┤_Č╚.Ą½▀\ė├š²æB─Ż║²öĄĘ©╚į╚╗ėąā╔éĆā׳cŻ║ó┘═©▀^ļ`ī┘Č╚Ū·ŠĆ─▄ī”Ė„╬█╚ŠĄ╚╝ē├µĘeš╝▒╚ėą▒╚▌^£╩┤_Ą─£yČ╚Ż¼─▄▌^×ķ├¶ĖąĄžĮyėŗ│÷蹊┐ģ^ė“Ęų▓╝śO╔┘Ą─╬█╚ŠĄ╚╝ē├µĘeš╝▒╚;ó┌ę▓─▄į┌ę╗Č©ų├ą┼╦«ŲĮŽ┬ė├ę╗éĆģ^ķgöĄüĒ▒Ēš„ģ^ė“═┴╚└ųžĮī┘┐é¾w╬█╚Š│╠Č╚Ż¼─▄Ė³×ķ╚½├µĄžĘ┤ė│ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚Ż¼įuārĮY╣¹╦∙║Ł╔wĄ─ą┼ŽóĖ³╝ė╚½├µ.
ĪĪĪĪ║╦├▄Č╚╣└ėŗät═╗ŲŲ┴╦─Ż║²öĄī”Ęų▓╝Śl╝■Ą─Ž▐ųŲŻ¼ī”╚╬║╬Ęų▓╝ą╬╩ĮĄ─öĄō■Š∙─▄Įyėŗ│÷╦∙ėą┐╔─▄ųĄĄ─Ė┼┬╩├▄Č╚Ż¼▓ó═©▀^ę╗Č©Ą─╣½╩Į▐D╗»Ū¾Ą├įōųžĮī┘Ą─ģ^ė“┐é¾w╬█╚Š│╠Č╚ęį╝░Ė„╬█╚Š╝ēäe├µĘeš╝▒╚.Å─łD 3Ą─ĮY╣¹┐╔ų¬Ż¼įuārĮY╣¹Ą─£╩┤_Č╚─▄į┌Ū░ā╔ĘNĘĮĘ©╗∙ĄA╔Žėąę╗Č©╠ßĖ▀Ż¼ŪęÅ─ś╦£╩▓Ņ╔Ž┐╔ęį┐┤│÷Ż¼║▄║├Ą─▒Ż│ų┴╦śė▒ŠöĄō■Ą─ĘĆČ©ąįŻ¼ę“┤╦Ż¼║╦╣└ėŗĄ─įuārĮY╣¹─▄Ė³£╩┤_ĄžĘ┤ė│蹊┐ģ^═┴╚└ųžĮī┘╬█╚ŠīŹļHŻ¼Ą½╦³ėąā╔éĆ╚▒³cŻ║ę╗╩Ūėŗ╦Ń┴┐▒╚▌^┤¾Ż¼╩ųäėėŗ╦ŃŲüĒ║▄Ę▒¼ŹŻ¼═©│ŻąĶę¬═©▀^│╠ą“üĒų¦│ų▀\╦ŃŻ¼┐╔┐╝æ]ĮĶų·▄ø╝■ŠÄ│╠üĒīŹ¼F;Č■╩Ū┤░īÆųĄĄ─┤¾ąĪī”║╦╣└ėŗĄ─ą¦╣¹Ųų°øQČ©ąįū„ė├Ż¼Ą½╩Ū┤░īÆĄ─║Ž└Ē╣└ėŗųĄ═∙═∙╩Ū▌^ļy┤_Č©Ą─.║╦├▄Č╚╣└ėŗĘĮĘ©Ą──Żą═╝▄śŗ▌^×ķņ`╗ŅČÓūāŻ¼═¼Ģrė╔ė┌╣└ėŗ╩Į┐╔ęįę└┘ć┤·┤a│╠ą“īŹ¼FŻ¼į╩įS╦³Ą─╣└ėŗ▀^│╠Ė³×ķÅ═ļsŻ¼╣╩ėąų°║▄┤¾Ą─Ė─įņ┐šķg.▒╚╚ń═§Į╚╗Ą╚(2005)▀\ė├Ą³┤·╦ŃĘ©ī”║╦║»öĄ─Żą═▀Mąąā×╗»Ż¼═©▀^ī”║╦├▄Č╚║»öĄ▀MąąĄ³┤·Ż¼▀Mę╗▓Į╠ßĖ▀ģ^ė“═┴╚└ųžĮī┘╬█╚Š│╠Č╚įuārĄ─£╩┤_Č╚Ż¼Ķbė┌Ųõ▀\╦Ń┴┐į┌║╦├▄Č╚╣└ėŗĄ─╗∙ĄA╔Žėųėą┴╦öĄ┴┐╝ēĄ─į÷╝ėŻ¼į┌▌^ČÓųĖś╦┼cśė▒ŠöĄĄ─ŪķørŽ┬įuārą¦┬╩Ģ■▒╚▌^Ą═Ż¼╚ń║╬į┌▒ŻūC£╩┤_Č╚Ą─═¼ĢrŻ¼╠ßĖ▀║╦╣└ėŗĄ³┤·╩ĮĄ─įuārą¦┬╩╩ŪųĄĄ├▀Mę╗▓Į蹊┐Ą─å¢Ņ}.Š▀¾wģóęŖ╬█╦«īÜ╔╠│Ū┘Y┴Ž╗“http://www.bnynw.comĖ³ČÓŽÓĻP╝╝ąg╬─ÖnĪŻ
ĪĪĪĪ5 ĮYšō
ĪĪĪĪģ^ė“═┴╚└ųžĮī┘╬█╚Š▓╗═¼įuārĘĮĘ©Ą─ĮY╣¹ėą╦∙▓╗═¼Ż¼Ė„ĘĮĘ©į┌įuār▒ŃĮ▌ąįĪóĮY╣¹Ą─£╩┤_Č╚║═░³║¼ą┼ŽóĄ─╚½├µąįĘĮ├µę▓ėą╦∙▓Ņ«ÉŻ║
ĪĪĪĪ1)║åå╬öĄ└ĒĮyėŗįuār▒ŃĮ▌ąįūŅĖ▀Ż¼Ą½ĮY╣¹£╩┤_Č╚▌^Ą═Ż¼ī”Ė„╬█╚ŠĄ╚╝ē├µĘeš╝▒╚Ą─£yČ╚▓╗ē“£╩┤_Ż¼Ģ■▀z┬®čąŠ┐ģ^ā╚Ęų▓╝śO╔┘Ą─╬█╚ŠĄ╚╝ē├µĘeš╝▒╚Ż¼▓óŪęų╗─▄Ą├│÷╬©ę╗ųĄŻ¼ĮY╣¹╦∙░³║¼ą┼Žó▌^╔┘.
ĪĪĪĪ2)æ¬ė├š²æB─Ż║²öĄĘ©įuār─▄═©▀^ļ`ī┘Č╚Ū·ŠĆ─▄ī”Ė„╬█╚ŠĄ╚╝ē├µĘeš╝▒╚ėą▒╚▌^£╩┤_Ą─£yČ╚Ż¼┤╦═Ōę▓─▄į┌ę╗Č©ų├ą┼╦«ŲĮŽ┬ė├ę╗éĆģ^ķgöĄüĒ▒Ēš„ģ^ė“═┴╚└ųžĮī┘┐é¾w╬█╚Š│╠Č╚Ż¼įuārĮY╣¹╦∙║Ł╔wĄ─ą┼ŽóĖ³╝ė╚½├µŻ¼ĮY╣¹╦∙░³║¼ą┼ŽóūŅČÓŻ¼Ą½╗∙ė┌š²æB─Ż║²öĄĘ©┼c║åå╬öĄ└ĒĮyėŗĄ─┐é¾w╬█╚Š│╠Č╚įuārĮY╣¹Ų½▓Ņę╗ų┬Ż¼ĮY╣¹£╩┤_Č╚▌^Ą═Ż¼▓óŪęš²æB─Ż║²öĄĘ©▓╔ė├▌^×ķÅ═ļsĄ─öĄīW─Żą═Ż¼įuār▒ŃĮ▌ąį▀hĄ═ė┌║åå╬öĄ└ĒĮyėŗ.┼cš²æB─Ż║²öĄĘ©ŽÓ▒╚Ż¼╚²ĮŪ─Ż║²öĄĘ©įuārĮY╣¹Š▀ėą▌^ÅŖĄ─▓©äėąįŻ¼įuārĮY╣¹▌^▓Ņ.
ĪĪĪĪ3)║╦├▄Č╚╣└ėŗĮY╣¹£╩┤_Č╚ūŅĖ▀Ż¼įōĘĮĘ©Ž┬蹊┐ģ^As║═Cd┐é¾w╬█╚ŠįuārĄ─ŲĮŠ∙Ąž└█ĘeųĖöĄŽÓī”ė┌ģóššųĄĄ─Ų½▓ŅāHĘųäe×ķ10.7%║═15.4%Ż¼Ą½╩Ū║╦├▄Č╚╣└ėŗ─Żą═ėŗ╦ŃūŅ×ķÅ═ļsŻ¼ąĶę¬═©▀^│╠ą“üĒų¦│ų▀\╦ŃŻ¼įuār▒ŃĮ▌ąįūŅ▓ŅŻ¼▓óŪęų╗─▄Ą├│÷╬©ę╗ųĄŻ¼ĮY╣¹╦∙░³║¼ą┼Žó▌^╔┘.═¼Ģrī”║╦├▄Č╚╣└ėŗą¦╣¹Ųų°øQČ©ąįū„ė├Ą─┤░īÆ║Ž└Ē╣└ėŗųĄ═∙═∙╩Ū▌^ļy┤_Č©Ą─Ż¼Ą½ė╔ė┌Ųõņ`╗ŅČÓūā─Żą═╝▄śŗ║═ėŗ╦Ń┐╔ęįę└┘ć┤·┤a│╠ą“īŹ¼FĄ─╠ž³cŻ¼║╦├▄Č╚ĘĮĘ©ėąų°║▄┤¾Ą─Ė─įņ┐šķg.

